Prefácio
Esse foi um material que me foi pedido insistentemente pelo Twitter. Com a pouca disponibilidade de livros e cursos gratuitos em português sobre Java, muitos que não tem acesso a lingua inglesa acabam sem poder estudar. Por isso elaborei esse material.
Ao escrever, tenho em mente que meu público alvo é alguém completamente leigo e desejo apresentar algum conteúdo sobre computação.
Espero que você aproveite esse material.
Victor Emanuel Perticarrari Osório
Como ler esse livro
Esse livro foi pensado para ser uma apresentação informal. Cada capitulo vamos tratar de um tema especifico, mas a forma de apresentação será como se eu e você estivéssemos sentado na mesa de um bar ou de um café. Eu sempre que vou ensinar algo tento reproduzir a forma que aprendi muitas das disciplina da universidade, tomando um café na casa de amigos.
Em cada capítulo existirão alguns exercícios.
— Mas não tem exercício em uma conversa de bar?!!?
Não?! Ora, já viu os guardanapos da mesa? Dá pra escrever e ler neles. Logo assim que você ver um exercício, você pode rascunhar uma resposta. Mas se lembre que todos os exercícios vão estar em um único repositório, o github.com/vepo/java-101-codigo. Para ver todos os exercícios em ordem, faça uma busca por "// [EXERCÍCIO]". Você encontrará um método vazio onde deverá colocar sua implementação, depois de feito, rode o comando mvn clean test e verá se sua implementação passou ou não no teste.
É muito importante exercitar. Você não será um bom desenvolvedor se não se exercitar. Antes de ler esse livro é importante saber que não existem gênios da computação como os do filmes de Hollywood. Aquilo é tudo mentira, os verdadeiros gênios são pessoas que ficaram anos estudando matemática, física, lógica e computação para que conseguissem formular alguma teoria ou escrever algum programa. Não admire personagens como o Elliot Alderson de Mr. Robot, ele é apenas um personagem de ficção. Admire pessoas como Ada Lovelace, Alan Turing, Edsger Dijkstra, Linus Torvalds e Donald Knuth. São essas pessoas que fizeram o mundo da programação melhor.



Como começar a aprender
A intenção desse material é te apresentar o básico sobre Java oferecendo ferramentas para que você possa aprender a programar. Nenhum material por sí só fará o trabalho completo, para que você possa se tornar um desenvolvedor é preciso muito exercício, por isso vá lentamente avançando sobre os tópicos propostos e fazendo todos os exercícios propostos.
Nesse sessão você vai aprender:
-
O que é Java
-
Como criar seu primeiro programa Java
Nos últimos meses muitas pessoas vem me perguntando por onde começar a desenvolver Java. Eu sei que existem vários cursos na internet que tem essa resposta e não quero me propor a criar um curso Java. Creio que o conhecimento deve ser livre e sem escassez. Por isso vou te apresentar o básico que você deve saber sobre Java.
Eu vou tentar seguir a ordem dessa thread que fiz em dezembro.

Java é um ecossistema
Muitos tendem a querer comparar Java com outras linguagens. Alguns tem a pretensão de comparar Java com linguagens como Javascript ou mesmo Scala. Esse é um erro crasso! Essa comparação não tem sentido porque o Java não é apenas uma linguagem, mas um ecossistema.
Primeiro para entender melhor vamos tentar compreender melhor o que é uma linguagem de programação…
Quando a computação eletrônica começou a se popularizar, existiam inúmeras plataformas e cada uma delas haviam um conjunto de instruções. Para desenvolver qualquer software era preciso conhecer o hardware e o conjunto de instruções que existem naquele hardware. Quer ver um exemplo? Tenta navegar no código da Apollo 11 para tentar entender algo. É praticamente impossível, até mesmo para quem já desenvolveu em Assembly. Isso acontece porque o conjunto de instruções e a arquitetura do hardware são completamente diferentes das máquinas que temos hoje.

Com o tempo as máquinas ganharam um padrão, tanto de processadores como de Opcodes. Hoje sabemos que existe um processador, um barramento, memória, registradores, etc… Esses componentes variam um pouco de arquitetura pra arquitetura, mas eles continuam seguindo um padrão. Abaixo você pode ver a documentação de um opcode.

— Cara qual a relação disso com Java?
Bom, vamos lá! Eu vou chegar lá! Eu prometo! Tudo que um computador reconhece são opcodes! Nenhum computador entende nenhuma linguagem de programação. Ah, mas você vai me dizer que algumas pessoas desenvolvem assembly… Sim! Mas mesmo para quem faz esses programas é preciso transcrever o programa em linguagem de máquina. Por exemplo, no opcode acima, o computador não sabe o que é NOP, ele só sabe que a operação 01 não deve produzir nenhum efeito. Então todo programa precisa ser compilado para uma série de instruções que chegam a praticamente o formato de máquina. Estou falando do famoso EXE do Windows. E esses programas também dependem de uma série de bibliotecas do sistema operacional para o qual foram compilados.
Até 1990 era comum um programa ser compilado para uma máquina especifica. Quem já trabalhou com Linux nos anos 2000 sabe o que é isso, você tinha que baixar o código fonte de um programa e compilar ele para a sua distribuição pois na maioria dos casos as versões de dependência eram muito especificas. Por isso uma grande empresa do Vale do Silício teve uma grande ideia! E se escrevêssemos uma linguagem em que ao se escrever um código ele poderá ser executado em qualquer lugar?
O ano era 1991 e a Sun já começava a se preparar para embarcar software em dispositivos portáveis e eletrodomésticos. Para isso era preciso de uma linguagem em que se pudesse criar programas sem nenhuma dependência com a arquitetura do processador e nem com o sistema operacional. Mas existia um grande desafio: como fazer para encapsular toda a lógica do hardware e do sistema operacional? Por isso surgiu algo que é tão importante quanto a linguagem Java: a Java Virtual Machine! Ou JVM para os mais íntimos…
A JVM é um programa que lê um conjunto de classes e executa como se fosse um processador em alto nível. Ela tem uma arquitetura similar a uma máquina e instruções, como se fosse um processador. Se você for curioso, pode ler a especificação dela, pois é aberta e pode ser acessada por qualquer fornecedor que queira porta ela em seu sistema operacional.
— Ah, mas Java nem é tão popular!
Então agora para e olha para o transformador que existe na sua rua… E se eu te dissesse que é provável que existe uma JVM rodando perto dele para monitorar esse transformador específico? Você acreditaria? Em algumas cidades isso existe. E só é possível porque a JVM é portátil em qualquer tipo de dispositivo.
Como eles tinha requisitos de portabilidade para criar o Java, foi preciso criar uma máquina virtual poderosa e é ela quem tem grande parte do crédito da popularidade da linguagem. Ao abstrair as particularidades de vários sistemas operacionais e hardwares, foi possível se economizar tempo escrevendo e compilando código.
— Então você tá falando que o Java é famoso só por causa da JVM?
Óbvio que não! A JVM já vem com uma biblioteca padrão que é muito poderosa. Podemos ter acesso a biblioteca de coleções que é poderosa, a biblioteca de Reflections foi a base da grande maioria dos frameworks dos anos 2000, etc… A JVM era poderosa e ela era parte do que chamamos Java. Ela era tão boa que surgiram linguagens que compilavam para rodar JVM e algumas delas são bem populares como: Kotlin, Groovy, Scala e Clojure.
— Ah, mas Java é chato. Não dá nem pra escrever um programa sem ter um objeto! Porque tem que sempre escrever um objeto? Quem teve essa ideia infeliz?
Eu poderia colocar essa pergunta como um ageísmo, mas eu prefiro o tempo esnobismo cronológico. Mas você está certo! Na minha humilde opinião, essa ideia é infeliz! Hoje nós sabemos disso porque a experiência desenvolvendo na linguagem Java nos mostrou isso. Quando ela foi desenvolvida a crença comum era de que Orientação Objeto era a panaceia para todos os males da computação. Se quiser reclamar, pode! Mas lhe garanto que não foi a pior ideia envolvendo OO, tentaram criar um banco de dados OO. Isso é bem pior do que escrever uma linguagem puramente OO.
Houveram projetos focados em fazer que componentes fosse a principal forma de desenvolvimento de software. Se acreditava que toda programação seria feita através do arrasto e do clique do mouse. Foi muito esforço para que não fosse mais preciso escrever código e nós estamos em 2022 escrevendo código. Quando o JavaBeans foi criado, a intenção era que ele pudesse ser manipulado por uma ferramenta visual, a BeanBox. Seria uma IDE que se conectaria vários componentes para que a dependência do desenvolvimento fosse reduzida. Como vemos pela história: deu errado! Mas esse esforço gerou muitas boas tecnologias que temos hoje.
Java Beans é uma especificação que deu origem ao que conhecemos hoje como Jakarta EE. É o falecido Java EE! É um modelo de programação em que seu código não fica dependente de um framework, da mesma forma que seu código não é dependente de uma máquina. Hoje é possível você escrever um programa para Quarkus e usar o mesmo código para OpenLiberty.
Já que falamos um pouco da história do Java, vamos começar a escrever nossa primeira linha Java?
Instalando tudo…
Para desenvolver programas Java é preciso instalar a JDK. JDK é a sigla para Java Development Kit que são uma série de programas para compilar, empacotar e monitorar seu programa Java. Desde de 2017 o Java adotou um processo chamado Release Train, em que uma nova versão é lançada a cada 6 meses com as funcionalidades prontas, então não gaste tempo procurando qual versão instalar… Você precisa de apenas uma coisa: o SDKMan!. Com ele é possível instalar qualquer versão de Java que você deseja e algumas outras ferramentas como vamos citar mais a frente.
Outra habilidade importante é saber usar a linha de comando, você pode ser um desenvolvedor sem usar ela, mas eu recomendo ter um pouco de intimidade com o Bash e usar constantemente.
— Bash não é do Linux?! Eu uso Windows e não quero mudar meu sistema operacional!
Calma. Se você usa Windows… Tá errado! Brincadeira! hehehe Você pode usar Windows, eu mesmo uso Windows (não por livre e espontânea vontade). Para usar Bash no Windows você pode instalar o cliente GIT que ele já vem com uma ferramenta chamada Git Bash, um console MinGW que é um porte dos programas GNU para Windows.
Para desenvolver, é recomendável que você use uma IDE. IDEs ou Integrated Development Environment (Ambiente de Desenvolvimento Integrado) são programas que integram editores de textos e ferramentas para desenvolvimento, build e analise de código. Escolha a que você mais gosta. Todas as IDEs relevantes no mercado tem suporte a Java.
— Ah, mas eu não posso usar o Notepad++?!?
Pode, mas você precisa de uma IDE porque é mais fácil desenvolver usando ferramentas. Elas provem funcionalidades que diminuem o número de bugs e facilitam o desenvolvimento como fazer a marcação da linguagem (o famoso code highlight) e para propor código (o famoso auto-complete). Desenvolvedores experientes preferem comodidade porque os problemas já são complexos demais para ficar perdendo tempo. Eu recomendo usar ou o Eclipse, o IntelliJ Idea ou o VS Code. As três IDEs são boas.
Usando uma IDE você pode construir seu projetinho Java, mas será muito difícil compartilhar ele com outras pessoas ou mesmo criar um executável a partir dele. Para facilitar a build do seu projeto existem ferramentas de gerenciamento de build: o Maven e o Gradle. Para instalar ele, procure no SDKMan!. Usando Maven/Gradle você pode definir o seu projeto e as dependências dele em um arquivo e ele será responsável pro baixar todas as dependências, compilar e gerar o que você precisa para colocar o seu software em produção.
Logo em resumo, o que você precisa é:
-
SDKMan!
-
Maven ou Gradle
-
Java
-
Uma boa IDE (Eclipse, IntelliJ IDEA ou VS Code)
Construindo meu primeiro programa Java
Então agora que você sabe que o Java é mais que uma linguagem, vamos escrever nosso primeiro código Java?
Se você quiser aprender, recomendo abrir sua IDE preferida e criar um projeto Java. Tente explorar sua IDE, ela tem uma infinidade de recursos que muitas vezes são poucos conhecidos principalmente por desenvolvedores mais experientes. Vou demonstrar primeiro como criar usando o IntelliJ, depois usando o Eclipse e por fim usando o Gradle e o Maven. Se você deseja apenas estudar, sinta-se a vontade para usar apenas a IDE, mas se você usar um sistema de build será mais fácil você trabalhar em equipes e seu projeto terá uma aparência mais "profissional".
Usando o IntelliJ
Com o ItelliJ, selecione Novo Projeto e você verá a tela abaixo. Você precisa adicionar o nome do projeto (Name) e o local em que deseja criar o projeto (Location). Eu recomendo você ter uma pasta separada para todos os seus projetos.

Na tela acima, temos algumas opções que são importantes. A primeira delas é que você pode escolher o sistema de build do seu projeto. O IntelliJ já tem um sistema de build próprio, mas você pode usar Maven ou Gradle. A segunda opção é que você pode escolher a versão da JDK que você vai usar. A JDK é a ferramenta que te possibilitará desenvolver Java, ela contém todos os programas para compilar seu código, executar, debugar e muitas outras ferramentas que podemos falar mais a diante. O IntelliJ permite você selecionar a JDK e fazer o download dela. Eu recomendo você usar a versão mais recente e escolher a Oracle OpenJDK como vendor. Depois você pode escolher já inicializar esse projeto como um repositório git (Create Git repository) ou iniciar o projeto com um código de exemplo (Add sample code).
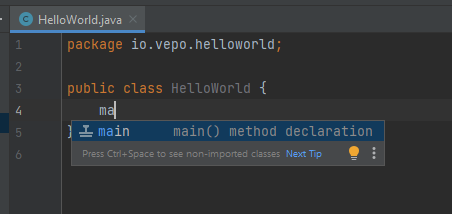
Depois de criado o projeto, você terá que adicionar uma classe ao projeto. Todo programa Java precisa de um método de entrada chamado main. Apesar de muitos criticarem essa limitação, isso era comum quando o Java foi desenvolvido. Hoje, na verdade, o Java não tem essa limitação, você pode usar o JShell e importar um arquivo jsh. Para criar sua primeira classe, selecione o botão direito do mouse na pasta src e depois selecione New → Java Class.

Ao selecionar uma nova classe, será necessário dar um nome a ela. O nome de uma classe é o que chamamos de Fully Qualified Name, ele é composto pelo nome do pacote e o real nome da classe, no caso estou criando o pacote io.vepo.helloworld e a classe HelloWorld. Vamos falar mais sobre classes e pacotes quando formos falar de Orientação a Objetos (eu prometo falar disso, tenham paciência!).
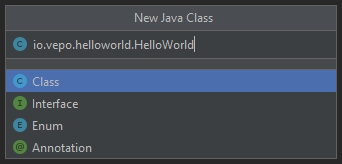
Criada a classe, vou te apresentar uma funcionalidade muito importante. Abra o editor de texto posicione o cursor para editar o texto dentro da classe, adicione o texto ma e use a funcionalidade mais fabulosa que se chama auto-complete selecionando CTRL+SPACE! Magicamente a IDE vai compreender qual é o contexto e vai propor o que você deve escrever. Agora siga para o último snippet desse post. (snippet significa trecho, é normalmente um significado para um trecho de código que serve de exemplo simples).
Usando o Eclipse
Eclipse é uma IDE que pode parecer ultrapassada, mas ela tem uma relação intrínseca com o Java, hoje uma nova versão do Java é liberado pela Oracle semestralmente, mas para que a Oracle conseguisse essa proeza (antes demorava anos) ela acabou deixando liberando o Java EE para Eclipse Foundation sob o nome de Jakarta EE. Por enquanto você não precisa saber de nada disso, só lembre que Eclipse é a IDE da Eclipse Foundation que controla alguma coisa do Java!
Porque eu citei o Java EE? Porque é provável que ao tentar fazer o download do Eclipse você veja a opção Enterprise como disponível. Você não precisa por enquanto de uma versão enterprise, tudo que você precisa é do Java Padrão (ou Java Standard Edition, SE para os mais íntimos).
Assim, ao iniciar o Workspace do Eclipse para Java você verá a opção para criar um novo projeto Java.

Ao selecionar, você entrará no Wizard de criação de um novo projeto. Semelhantemente ao IntelliJ, você terá que escolher um nome para o projeto e um local, a diferença é que no Eclipse o local padrão é o workspace. Você não precisa criar o projeto no workspace, você pode usar qualquer diretório, mas será no workspace que o Eclipse salvará alguns arquivos que definem como você está usando o mesmo, por isso caso você tenha mais de um contexto de desenvolvimento, você pode usar vários workspaces e trocar quando necessitar trocar de contextos. Por exemplo, você tem o workspace do trabalho e o workspace da faculdade, ou um workspace para cada projeto que você está trabalhando.
Você também pode selecionar a JDK que vai usar. Eu recomendo selecionar Finish, pois as outras telas do wizard são usadas para adicionar novas bibliotecas ou mudar a estrutura de diretórios do projeto.

Da mesma forma que o IntelliJ você tem que selecionar o botão direito do mouse na pasta src e depois selecione New → Java Class.

E por fim dar um nome a classe, mas diferente do IntelliJ, o Eclipse dá mais liberdade para criar a classe, como já adicionar o método main.

Com a classe, você também pode usar o auto-complete. Eu pessoalmente acho essa funcionalidade melhor no Eclipse que no IntelliJ. Aliás, se você usa VS Code, você está usando essa funcionalidade porque o VS Code usa o servidor de código do Eclipse.
Uma desvantagem de usar eclipse é que ele não usa coordenadas Maven como veremos a seguir para definir as dependências.
Usando o Gradle
O erro mais comum de quem trabalha em grandes times é baixar uma IDE e criar um projeto Java. 🤯 Eu fiz isso por muito tempo, até descobrir que é só dor de cabeça. Quando fazemos isso acabamos por obrigar todo mundo do time a usar a mesma IDE e a ter que alterar arquivos de configuração complicados para fazer o projeto funcionar. Por isso, é mais fácil você usar o Maven ou o Gradle. Usar um sistema de build não significa não usar uma IDE, as IDEs conseguem importar a estrutura desses projetos e a partir daí toda as configurações serão feitas usando o sistema de build, mesmo se forem feitas através da IDE. A minha opção pessoal é o Maven, mas é por pura comodidade pois sou usuário há bastante tempo. Já tive vontade de aprender Gradle, mas… Bom… Vamos ver o Gradle!
O Gradle te permite gerar toda a estrutura do seu projeto automaticamente, basta executar gradle init no diretório da aplicação e seguir respondendo as perguntas. Eu recomendo criar uma application Java não quebrada em submódulos usando Groovy e JUnit Jupyter conforme as opções abaixo.
$ gradle init
Select type of project to generate:
1: basic
2: application
3: library
4: Gradle plugin
Enter selection (default: basic) [1..4] 2
Select implementation language:
1: C++
2: Groovy
3: Java
4: Kotlin
5: Scala
6: Swift
Enter selection (default: Java) [1..6] 3
Split functionality across multiple subprojects?:
1: no - only one application project
2: yes - application and library projects
Enter selection (default: no - only one application project) [1..2] 1
1: Groovy
2: Kotlin
Enter selection (default: Groovy) [1..2] 1
Select test framework:
1: JUnit 4
2: TestNG
3: Spock
4: JUnit Jupiter
Enter selection (default: JUnit Jupiter) [1..4] 4
Project name (default: meu-projeto-gradle):
Source package (default: meu.projeto.gradle):
BUILD SUCCESSFUL
2 actionable tasks: 2 executedO próximo passo é abrir o diretório em uma IDE, ver a estrutura criada. Para saber como usar o Gradle, use o comando gradle tasks e com um pouco de Google Translator você poderá saber tudo o que fazer com o projeto.
Eu nunca tinha usado o Gradle e ele me parece bem mais fácil que o Maven. Você precisa ficar atento ao arquivo build.gradle que é onde todas as propriedades são definidas. Elas serão bem similares as definidas no nosso projeto Maven, mas em uma linguagem diferente, o Groovy.
Usando o Maven
Com o Maven você pode facilmente criar um projeto Java e compilar ele independente de IDE. O Maven também vai se encarregará de encontrar todas as dependências em suas versões e dependências. Então para criar um projeto Java basta criar um arquivo pom.xml e um arquivo Java, como na estrutura abaixo.
.
├── src
│ └── main
│ └── java
│ └── io
│ └── vepo
│ └── helloworld
│ └── HelloWorld.java
└── pom.xmlPara quem não conhece o Maven (dê uma olhada nesse simples tutorial), ele vai gerenciar a build do seu projetos Java. O arquivo pom.xml vai conter as informações básicas do projeto e as dependências. Você pode achar estranha a estrutura de diretórios, mas ela é bastante útil para evitar configurações. O Maven atua por um padrão chamado Convenção sobre configuração, ao invés de colocar todas as configurações do projeto, basta seguir essa regrinha básica de estrutura de diretórios.
Para encontrar dependências Maven, é possível procurar no mvnrepository.com. Cada dependência é definida pelas coordenadas groupId, artifactId e version e elas podem ser encontradas diretamente no mvnrepository.com, como é o caso do Kafka Clientes mvnrepository.com/artifact/org.apache.kafka/kafka-clients. Observe o padrão da URL, mvnrepository.com/artifact/{groupId}/{artifactId}. É possível também adicionar a versão na URL mvnrepository.com/artifact/{groupId}/{artifactId}/{version}. Isso facilita a busca pode dependências.
Para facilitar na execução, já estou colocando o plugin org.codehaus.mojo:exec-maven-plugin corretamente configurado para apontar para a classe io.vepo.helloworld.HelloWorld, assim para executar basta usar mvn clean compile exec:java.
<?xml version="1.0"?>
<project xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<modelVersion>4.0.0</modelVersion>
<groupId>io.vepo.helloworld</groupId> <!-- Use um identificado para sua empresa -->
<artifactId>hello-world</artifactId> <!-- Use um identificado para seu projeto -->
<version>1.0.0-SNAPSHOT</version> <!-- Use um versão baseada em https://semver.org/lang/pt-BR/ -->
<name>Hello World!</name> <!-- Dê um nome legal ao seu projeto -->
<properties>
<!-- Caso você se uma versão de Java diferente, altere a linha abaixo -->
<java.version>18</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<maven.compiler.parameters>true</maven.compiler.parameters>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
</properties>
<dependencies>
<!-- Procure as dependências no mvnrepository.com -->
</dependencies>
<build>
<finalName>hello-world</finalName> <!-- Esse nome é usado para construir o jar final -->
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<mainClass>io.vepo.helloworld.HelloWorld</mainClass>
</configuration>
</plugin>
</plugins>
</build>
</project>Observe como é simples… Com isso todas as configurações ficam disponíveis em um único arquivo que pode ser usado pela sua IDE preferida.
Agora é só criar a classe como o exemplo abaixo e pronto! Execute mvn clean compile exec:java e você verá o resultado na tela.
package io.vepo.helloworld;
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello World!");
}
}Agora caso você queira criar um programa usando um framework… Eu recomendo você procurar o tutorial desse framework. Talvez você precisará escrever um main específico ou mesmo usar um conjunto de anotações, adicionar uma série de dependências e um plugin.
Exercícios
Os exercícios são propostos como forma de validar que você pode ir para o próximo passo. Nessa sessão vamos apenas pedir para você configurar o ambiente, para isso:
-
Configure usa IDE preferida
-
Crie um programa Java usando a IDE
-
Crie um programa Java usando um sistema de build (Maven ou Gradle)
-
Tente criar um programa linha de comando usando os código de escape ANSI. Você pode fazer usando o
System.out.printlnou uma biblioteca (por exemplo a github.com/fusesource/jansi) -
[Opcional] Tente criar e rodar um projeto Spring Boot usando o Spring Initializr
-
[Opcional] Tente criar e rodar um projeto Quarkus usando o Quarkus - Start coding with code.quarkus.io
-
[Opcional] Tente criar e rodar um projeto Microprofile.io usando Starter | MicroProfile
Próximos passos
Agora que você sabe como escrever e executar um programa Java, você pode conhecer um pouco mais da sintaxe da linguagem. Ela é baseada na linguagem C, mas tem algumas especificidades… Eu recomendei o tutorial do W3CSchools por ter ao menos uma listagem das principais construções do Java 8. Tente saber como declarar uma classe, um método, variáveis, quais são as principais estruturas de loop (for e while) e suas variações e por fim as estruturas lógicas (if e switch).
Depois conheça ao menos alguns dos pacotes básicos da linguagem, a documentação está disponível na internet. Eu recomendo que você comece pelo pacote java.util ele vai conter as classes básicas de coleções. No próximo post vamos focar exatamente nela!
A sintaxe
A intenção desse material é te apresentar o básico sobre Java oferecendo ferramentas para que você possa aprender a programar. Nenhum material por sí só fará o trabalho completo, para que você possa se tornar um desenvolvedor é preciso muito exercício, por isso vá lentamente avançando sobre os tópicos propostos e fazendo todos os exercícios propostos.
Nesse sessão você vai aprender:
-
O que é uma linguagem de programação e no que ela difere de uma linguagem natural
-
Os elementos básicos da sintaxe da linguagem Java
Anteriormente aprendemos o que é Java, porque precisamos de uma linguagem de programação e como criar nosso primeiro programa Java. Agora vamos aprender um pouco mais a sintaxe Java e sobre um assunto muito importante para qualquer desenvolvedor: algoritmos. Qualquer linguagem de programação tem uma sintaxe e você tem que respeitar ela por um motivo meio óbvio e muito importante: o computador é extremamente burro.
Linguagens Formais e Linguagem Natural
Antes de entender porque o computador é extremamente burro, vamos tentar diferenciar uma linguagem de programação das linguagens que usamos para conversar com outras pessoas. Se você nunca estudou formalmente o que é uma linguagem de programação, talvez seja preciso definir corretamente o que a difere de outras linguagens.
No dia a dia, nós somos acostumados a um tipo de linguagem que é extremamente maleável e pode ser compreendida mesmo que esteja formalmente errada. Eu posso omitir um objeto, inverter sujeito e predicado (todo mundo entendia o Mestre Yoda) e a comunicação continua acontecendo normalmente. Na nossa cultura, infelizmente, são raras as pessoas que amam estudar a estrutura de português, eu mesmo não sou uma delas apesar de gostar de leitura. Conhecer mais a língua que falamos não é comum porque podemos ser entendidos facilmente mesmo usando estruturas básicas e é uma atividade hercúlea e extremamente chata. O português por ser uma língua falada em locais bem diferentes é cheio de regras e excussões de difícil entendimento, a nossa língua é falada no Brasil 🇧🇷, Angola 🇦🇴, Cabo Verde 🇨🇻, Guiné-Bissau 🇬🇼, Guiné Equatorial 🇬🇶, Moçambique 🇲🇿, São Tomé e Príncipe 🇸🇹, Timor-Leste 🇹🇱, China 🇨🇳 e até em Portugal 🇵🇹. Esse texto mesmo, apesar de parecer correto, se passar por uma revisão profissional será alvo de várias correções sutis que faço porque são comuns na coloquialidade mas podem casuar pequenos desentendimentos na língua escrita, o mais comum deles é a troca de pessoa ao me referir a você leitor.
As línguas Português, Inglês, Mandarim, Japonês e até o Javanês são o que conhecemos como linguagens naturais, pois elas emergem da experiência humana e são compreendidas por humanos. Computadores não entendem essas linguagens, eles podem apenas capturar símbolos, mas eles não conseguem compreender.
— Ah, mas tem o GPT-3 que consegue ler e escrever bons textos.
Calma lá! É preciso entender como funciona um computador para não cair no jornalismo barato e marketing agressivo de companhias de Inteligência Artificial. GPT-3 não é aquilo que foi prometido e tem suas limitações. Eu recomendo ler o artigo "GPT-3, Falsário: o gerador de linguagem do OpenAI não tem ideia do que está falando" (se não lê inglês, use o Google Translator). O entendimento do que é uma linguagem de programação é muito importante, por isso vamos fazer uma analogia para demonstrar como lidar com a gramática delas.
Imagine que um computador é como um falante de português que está preso dentro de um quarto com um livro de regras. Sua função é, ao receber caixas com texto em chinês, deve consultar o livro de regras para identificar os símbolos no texto e formular uma resposta baseado nas regras e no texto recebido e enviar a resposta para fora do quarto. Esse homem não sabe chinês e nem consegue compreender o que ele está respondendo, ele só está seguindo as regras de quem escreveu o livro. O homem compreende a comunicação? Ao interlocutor fora do quarto, parece que o homem fala chinês?

Programas são o livro de regras que é escrito por programadores. Isso significa que, por melhor que seja um programa, um computador não tem compreensão do que está acontecendo. O interlocutor até poderá acreditar que o programa entende chinês, mas se houver alguma situação não prevista no livro de regras, não será possível formular uma resposta e o interlocutor ficará em dúvida.
Como já falamos, um computador é uma entidade extremamente burra. Ela só vai conseguir compreender as regras se elas forem muito bem escritas em uma linguagem muito bem estruturada. Essa linguagem vai ter uma sintaxe bem definida e se por algum motivo ela for violada o computador não será capaz de compreender. Ou seja, o computador não pode usar daquilo que todos os humanos tem: bom senso. Ele não vai conseguir compreender se um sujeito for omitido. É por esse motivo que as chamamos de Linguagens Formais.
Java, C, Javascript, PHP, Python, etc… são linguagens formais. Elas não emergem da experiência humana, mas são propostas por humanos para se comunicar com computadores. Um humano consegue identificar um erro em uma linguagem natural e mesmo assim compreender o que é proposto, mas um erro em uma linguagem formal impossibilita todo o processo. Se você quiser saber como definir uma linguagem formal, eu já escrevi sobre isso em "Como criar uma linguagem usando ANTLR4 e Java".
A Sintaxe Java
Agora vamos falar do Java… Java é uma linguagem que normalmente chamamos de C-Like, isso significa que ela herda muitas características do C. Se você nunca ouviu falar de C, não se preocupe, apesar dela ser uma das linguagens mais influente da história, ela não tem muito espaço no desenvolvimento web moderno, está nichada em desenvolvimento embarcado e nos drivers e kernel dos sistemas operacionais. Mas o C emprestou ao Java muito das estruturas que usamos no dia a dia e são nessas estruturas que vamos focar por enquanto.
O C é uma linguagem de propósito geral e estruturada. Isso significa que é possível escrever qualquer tipo de programa com ela, mas por suas características o estilo de programação mais comum é o imperativa. Quando falamos de paradigma imperativa dizemos que nosso programa está definindo a forma como as coisas devem ser feitas e não a definição formal da solução, como acontece com a programação declarativa. A programação declarativa está focada na transformação do dado, enquanto a programação imperativa irá ditar os passos que devemos fazer para transformar os dados.
Com o Java é possível programar das duas formas, mas como vamos estudar a sintaxe da linguagem vamos nos preocupar por enquanto apenas com a programação imperativa, por isso vamos deixar orientação a objetos e programação funcional para outro momento. Pensar no Java como uma linguagem imperativa é pensar que devemos escrever um programa que irá transformar os dados de acordo com os passos que definimos, então precisamos pensar em como esses dados serão transformados. Esse "como" é o que chamamos de algoritmo. Algoritmo é uma receita de bolo muito bem definida que transforma dados. Por "muito bem definida" entenda que ele deve ter uma entrada, uma saída e passos definidos, os passos serão definidos através da sintaxe.
Já falei que um computador é algo extremamente burro? Sim! Tudo que ele faz é ler um programa, executar uma instrução e executar a próxima instrução. Cada instrução altera o estado interno da aplicação, esse estado por sua vez é a memória do computador. Quando falamos de programação imperativa, como o fluxo da aplicação define os processos de transformação do dado a execução pode ter caminhos diferente dependendo dos dados. Em muitos casos o processo pode ser visualizado através de fluxogramas simples. Sempre que você for tentar entender um programa estrutural, você vai ter que ter em mente quais são os dados relevantes na execução e o fluxo da execução.

As estruturas que vamos falar são usadas para definir esse fluxo, como em todas linguagens C-like elas tem nomes em inglês mas elas refletem as decisões que devem ser feitas baseadas nos dados em memória. Essas estruturas são validadas em temos de compilação, mas se você usa uma boa IDE você vai ver se houver um erro durante a edição do seu código fonte. Enquanto essas estruturas não estiverem muito bem definidas, o programa não poderá ser compilado e por isso não poderá ser executado.
Para facilitar o entendimento do fluxo, abaixo listo todas as estruturas que vamos detalhar resumidamente com uma tradução livre to termo em português. Ao lado de cada uma temos a documentação oficial (para versão 8 do Java) com a especificação formal. Não se preocupe se você não conseguir entender a documentação. Eu fiz a tradução para que você possa compreender melhor, nunca a utilize porque isso não é comum, a não ser que você deseje aprender Potigol, a tradução serve para você ver que tem uma lógica na nomenclatura, é como se o código fosse um tipo de linguagem verbalizável.
1. Bloco (Block)
Um bloco de código é uma estrutura que pode ser tanto obrigatória quanto opcional. Essa estrutura é definida {} e dentro desse bloco teremos um novo escopo de variáveis assim como as instruções que vão definir esse bloco. Por escopo entenda que toda variável definida dentro de um bloco será conhecida apenas por aquele bloco e todo bloco definido dentro dele. Vamos ver a definição de variável no próximo tópico.
Observe o código abaixo. Nele temos os blocos B1 a B4. Os blocos B1 e B2 fazem parte de estruturas mais complexas e são obrigatórios, que no caso são uma classe e um método respectivamente (não vamos falar da definição de classe e método por enquanto). Já os blocos B3 e B4 são opcionais e estão aí para mostrar que podemos criar um bloco quando bem entendermos, apesar dessa não ser uma prática comum no desenvolvimento Java. 🤓
public class HelloWorldSintaxe { // B1
public static void main(String[] args) { // B2
System.out.println("Olá mundo");
String variavel = "abc";
System.out.println("Valor de variavel=" + variavel);
{} // B3: Bloco vazio
{ // B4
String variavel2 = "xyz";
System.out.println("Valor de variavel2=" + variavel2);
}
// System.out.println("Valor de variavel2=" + variavel2); // Se você
}
// private void x() return 1; // Bloco é obrigatório no caso de método, essa construção vai falhar
}Se você começar a brincar com esse código, vai ver que a variavel2 só pode ser usada dentro do B4. Isso é o que chamamos de escopo, ao finalizar a execução de B4 ela é completamente desnecessária e poderá ser eliminada da memória.
2. Declaração (Statement)
Se você pegar um código Java, ou de qualquer outra linguagem C-Like, vai perceber que o comportamento dele é sempre similar. Existe um método/função main que deve ter uma assinatura especifica e uma série de declarações.
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello World!");
}
}No código acima, temos o mais simples Hello World escrito em Java. Quando a JVM vai executar esse código será feito como é feito em qualquer outra linguagem imperativa, primeiro a JVM lê a primeira declaração, executa ela alterando o estado do programa, e depois executa a próxima até não existirem mais declarações ou o programa for finalizado por alguma instrução.
Podemos dizer que toda estrutura Java é uma declaração e toda declaração tem significado. Declarações em Java devem ser separadas por ; ou devem conter um Bloco de código. Tudo que devemos entender de uma declaração é que ela tem um significado e que elas são executadas em sequencia.
Vamos imaginar um outro código hipotético que é composto pela chama de 3 métodos. Tudo que podemos supor é que as três declarações são executadas em sequência, desde que não aconteça nada excepcional.
metodo1();
declaracao1();
metodo2();3. Definição de Variáveis (Local Variable Declaration)
Variáveis são posições da memória usadas para armazenar informações necessárias durante a execução do código. Uma variável pode ser de um tipo primitivo (byte, short, int, long, float double, boolean ou char) ou um objeto. Tipos primitivos diferem de objeto porque armazenam apenas um valor sem ter nenhum método associado a ele. Uma variável irá pertencer a um bloco de código e sua existência existe do momento da declaração até a finalização do bloco. Como falamos, variáveis são posições de memória, mas existem dois tipos de memória em Java, que vamos falar posteriormente, a heap e a stack. Tipos primitivos são declarados na heap, enquanto objetos são declarados na heap, isso significa que para tipos primitivos cada variável é uma posição única enquanto um mesmo objeto pode ser compartilhado por várias variáveis.
— Ein?!?!
Sim! A princípio é difícil de entender. Todo bloco de código possui um valor associado a uma variável, no tipo primitivo temos na variável o valor exato enquanto nos objetos temos uma referência ao valor. Vamos demonstrar por um exemplo? Dê uma olhada no código abaixo. Observer que uma definição de variável sempre é acompanhada no formato <tipo> <nome da variável> = <valor>;.
int x = 0; // x = 0
int y = x; // x = 0, y = 0
x = y + 20; // x = 20, y = 0
y = 10; // x = 20, y = 10
Usuario usr1 = new Usuário(1, "João"); // usr1 = Usuario[id=1, nome=João]
Usuario usr2 = usr1; // usr1 = Usuario[id=1, nome=João], usr2 = Usuario[id=1, nome=João]
Usuario usr3 = new Usuário(1, "João"); // usr1 = Usuario[id=1, nome=João], usr2 = Usuario[id=1, nome=João], usr3 = Usuario[id=1, nome=João]
usr1.setNome("João Doe"); // usr1 = Usuario[id=1, nome=João Doe], usr2 = Usuario[id=1, nome=João Doe], usr3 = Usuario[id=1, nome=João]
usr1 = null; // usr1 = null, usr2 = Usuario[id=1, nome=João Doe], usr3 = Usuario[id=1, nome=João]No código acima vemos os dois tipos de dados, temos a classe Usuario e temos o tipo primitivo int. Quando criamos uma variável do tipo primitivo a partir de outro valor, podemos alterar livremente o outro valor que a nova variável permanecerá inalterada. Mas o mesmo não acontece com a classe Usuario, que apesar de todos terem valores iguais, usr1 e usr2 por algum momento apontam para o mesmo objeto. usr3 nunca se altera porque é um objeto distinto mesmo tendo o mesmo valor que usr1 e usr2.
Na última linha do trecho de código usamos o valor null. null não é um tipo, apenas significa nulo em tradução livre, mas em computação significa a ausência de valor. É quando dizemos que uma variável não contem valor, ela não aponta para lugar nenhum. Variáveis que são tipos primitivos não pode ser nulas, elas deve sempre ter um valor associado.
4. Comentário (Comments)
Comentários são trechos de código que serão ignorados durante o processo de compilação. Apesar que alguns autores falam que todo comentário é uma falha, afirmação que eu discordo veementemente, eles são necessários para documentar informações que não podem ser documentadas no código. Tenha sempre em mente que comentários são necessários, com o tempo e a experiência você vai aprender sobre o que escrever nos comentários. Por enquanto vamos nos contentar em como comentar.
Existem 3 tipos de comentários em Java: 1. Comentários de fim de linha 2. Comentários tradicionais 3. Javadoc
Para criar um comentário em linha, adicione os dois caracteres // e tudo que você escrever até o fim da linha será desconsiderado durante a compilação. O exemplo abaixo foi retirado do código do Apache Kafka, apesar de estar em inglês ele contém informações relevantes ao código.
// Try to calculate partition, but note that after this call it can be RecordMetadata.UNKNOWN_PARTITION,
// which means that the RecordAccumulator would pick a partition using built-in logic (which may
// take into account broker load, the amount of data produced to each partition, etc.).
int partition = partition(record, serializedKey, serializedValue, cluster);Para criar um comentário tradicional, inicie com / e todo caractere até encontrar o final / será desconsiderado. Abaixo temos mais um comentário retirado do código do Apache Kafka, ele explica a decisão de não existir um break naquela posição como veremos mais a frente.
case REAUTH_RECEIVE_HANDSHAKE_OR_OTHER_RESPONSE:
handshakeResponse = (SaslHandshakeResponse) receiveKafkaResponse();
if (handshakeResponse == null)
break;
handleSaslHandshakeResponse(handshakeResponse);
setSaslState(SaslState.REAUTH_INITIAL); // Will set immediately
/*
* Fall through and start SASL authentication using the configured client
* mechanism. Note that we have to either fall through or add a loop to enter
* the switch statement again. We will fall through to avoid adding the loop and
* therefore minimize the changes to authentication-related code due to the
* changes related to re-authentication.
*/
case REAUTH_INITIAL:
sendInitialToken();
setSaslState(SaslState.INTERMEDIATE);
breakO Javadoc é um tipo especial de comentário tradicional que nos permite gerar uma documentação oficial a partir do código. Ele se diferencia do comentário tradicional por iniciar com /**, não apenas /, e pode estar acima de classes, métodos e campos. Javadoc segue uma linguagem de marcação deve ser usada sempre, pois além de poder ser usada como documentação oficial, ela também será exibida pelas IDEs em funcionalidades que irão lhe auxiliar durante o desenvolvimento. Javadoc também aceita tags HTML, as não tente usar CSS e Javascript.
No exemplo abaixo temos um trecho da documentação oficial do Apache Kafka. É interessante notar que o autor desse código se preocupou em descrever a funcionalidade do método, e os motivos pelo qual as exceções são lançadas, mas ignorou a descrição do parâmetro porque é intuitivo. Evite comentários desnecessários.
/**
* Get the partition metadata for the given topic. This can be used for custom partitioning.
* @throws AuthenticationException if authentication fails. See the exception for more details
* @throws AuthorizationException if not authorized to the specified topic. See the exception for more details
* @throws InterruptException if the thread is interrupted while blocked
* @throws TimeoutException if metadata could not be refreshed within {@code max.block.ms}
* @throws KafkaException for all Kafka-related exceptions, including the case where this method is called after producer close
*/
@Override
public List<PartitionInfo> partitionsFor(String topic) {}
Comentar código não é uma atividade simples, ela será trabalhada com a maturidade. Com o tempo você vai aprende que informações devem ser consideradas auxiliar ao código. Você não precisa comentar o que está no código, mas a informação que falta ao código, não é o como, mas o porque do código. Eu gosto de comentar pressupostos e escolhas arquiteturais porque em alguns meses eu não vou lembrar ou outra pessoa que pegar meu código também não vai saber o motivo de alguns escolhas.
5. Se (if)
Agora vamos ver a primeira declaração de fluxo que também é a mais comum. Mais conhecida como if, ou condicional, é composto por if (expressão booleana) <bloco> else <bloco>, onde expressão booleana é qualquer função que retorne um boolean ou uma expressão lógica que veremos em Operadores Lógicos. A expressão pode ser resumida para if (expressão booleana) <bloco> ou pode ser encadeada em várias outras declarações condicionais if (expressão booleana) <bloco> else if (outra expressão booleana) <bloco> else <bloco>.
int x = leNumeroInteiro();
if (x % 2 == 0) { // o operador % retorna o resto da divisão
System.out.println("O valor lido é par!");
} else {
System.out.println("O valor lido é impar!");
}
if (x % 3 == 0) {
System.out.println("O valor lido é múltiplo de 3!");
} else if (x % 3 == 1) {
System.out.println("O valor lido tem a forma f(x) = 3x + 1");
} else {
System.out.println("O valor lido tem a forma f(x) = 3x + 2");
}No exemplo acima temos 3 expressões lógica. A primeira calcula se o valor é par então logicamente o bloco else será executado para todo valor impar. A segunda calcula se o valor é divisível por 3, isso significa que o bloco else será chamado para todo valor não divisível, mas com o if encadeado fazemos a visão daquele que são no formato 3x + 1 e 3x + 2. Vamos ver as expressões mais a frente.
6. Enquanto (while)
Enquanto define que um bloco de código será executado até que uma expressão lógica seja falsa. A execução do bloco de código é feita continuamente logo depois do teste da expressão lógica. Exemplo?
int x = leValor();
while(x > 0) {
System.out.println("Valor é positivo!");
x = leValor();
}O bloco de código acima será executado continuamente até que venha um valor 0 ou negativo.
7. Faça enquanto (do-while)
O Faça enquanto funciona de forma bem similar, a diferença é que o teste é feito depois que o bloco de código é executado. Ele é muito similar a declaração anterior, a diferença é a ordem de execução entre o teste lógico e o bloco de código.
do {
executa();
} while (emExecução)8. Para (for)
O famoso for é um pouco mais complexo. Ele é composto por 3 blocos que podem ser chamados de inicialização, condição e passo. Ao iniciar será executado uma única vez o trecho de código inicialização e em cada iteração será executado o trecho de código condição, que deve retornar uma expressão booleana, depois será executado o bloco de código para depois ser executado o trecho passo. O exemplo mais comum é para se iterar em um array.
int[] array = new int[] {0 , 1, 2, 3, 4, 5};
for (int i = 0; i < array.length; i++) {
// bloco de código
}9. Escolha (switch)
O switch escolhe o código de acordo com o valor de uma variável. O switch é uma estrutura que pode facilmente induzir a erros porque cada bloco não é exclusivo, o fluxo de execução passar de um bloco ao outro até que seja encontrada a instrução break. Vamos ver um exemplo?
int x = leValor();
switch (x) {
case 1:
System.out.println("É igual a 1!");
case 2:
System.out.println("É maior ou igual a 2!");
case 3:
System.out.println("É maior ou igual a 3!");
case 4:
System.out.println("É maior ou igual a 4!");
case 5:
System.out.println("É maior ou igual a 5!");
default
System.out.println("É maior que 5 ou menor que 1!");
}O que aconteceria se o valor de x for igual a 3? Seriam executados os blocos de 3 até o default.
É maior ou igual a 3!
É maior ou igual a 4!
É maior ou igual a 5!
É maior que 5 ou menor que 1!Se quisermos um valor exato, podemos usar o break:
int x = leValor();
switch (x) {
case 1:
System.out.println("É igual a 1!");
break;
case 2:
System.out.println("É igual a 2!");
break;
case 3:
System.out.println("É igual a 3!");
break;
case 4:
System.out.println("É igual a 4!");
break;
case 5:
System.out.println("É igual a 5!");
break;
default
System.out.println("É maior que 5 ou menor que 1!");
}Agora você deve ter se perguntado porque no texto do bloco default eu usei menor que 1? Isso porque o switch não é usado para intervalos de valores, mas para valores exatos e caso nenhum valor seja igual aos valores declarados é chamado o bloco default.
Vale lembrar que o switch pode ser usado para números, enumeradores e qualquer valor constante, inclusive String.
10. Quebra e continua (break e continue)
Uma quebra deve ser chamada dentro bloco switch, while, do ou for. Ao se deparar com essa instrução o programa irá finalizar a execução do bloco externo imediatamente.
Vamos demonstrar isso com um exemplo básico? No código abaixo vamos criar um for que será finalizado usando break. Observe que o ponto de parada do for seria no máximo inteiro possível, mas através do break finalizamos em 10.
System.out.println("Iniciando for...");
for (int i = 0; i < Integer.MAX_VALUE; i++) {
System.out.println("Valor: " + i);
if (i == 10) {
break;
}
}Quando usamos break dentro de um switch evitamos que os blocos de códigos abaixo dele seja executados.
O continue tem um comportamento parecido, mas ao invés de finalizar o bloco será apenas finalizada a iteração. Ele só é aceito em iterações como while, do ou for. Vamos incrementar o exemplo acima para imprimir apenas números impares. Observe que no código abaixo foi preciso mudar a condição de execução do break porque ele nunca seria executado se usássemos i == 10.
System.out.println("Iniciando for...");
for (int i = 0; i < Integer.MAX_VALUE; i++) {
if (i % 2 == 0) {
continue;
}
System.out.println("Valor: " + i);
if (i > 10) {
break;
}
}Se você leu a documentação atentamente, viu que break e continue podem aceitar rótulos. O que isso significa? Vamos imaginar que temos um loop encadeado em que buscamos um valor dentro de uma matrix. Como as linhas dessa matrix são ordenadas, se o valor em uma coluna for maior que o valor desejado, podemos pular para próxima linha. A decisão do break e do continue é feita usando os rótulos que todo bloco de código aceita.
int[][] matrix = new int[][] {
{ 2, 2, 2, 3, 4, 5 },
{ 2, 4, 8, 8, 9, 9 },
{ 1, 2, 4, 5, 6, 8 },
{ 0, 3, 4, 8, 8, 9 },
{ 3, 4, 4, 6, 6, 9 },
{ 0, 3, 6, 7, 8, 8 },
};
linhas: for (int linha = 0; linha < matrix.length; ++linha) {
colunas: for (int coluna = 0; coluna < matrix[linha].length; ++coluna) {
if (matrix[linha][coluna] == 7) {
System.out.println("Número 7 encontrado! (" + linha + "," + coluna + ")");
break linhas;
} else if (matrix[linha][coluna] > 7) {
System.out.println("Desistindo da linha! (" + linha + "," + coluna + ")");
continue linhas;
} else if (matrix[linha][coluna] < 7) {
System.out.println("Pulando para próxima coluna! (" + linha + "," + coluna + ")");
continue colunas;
}
System.out.println("Código nunca executado!");
}
}Se não fosse usado um rótulo, o break e o continue iriam atuar somente no bloco de código mais interno.
11. Lance (throw)
O throw deve ser usado quando algo excepcional acontece. Algo inesperado, tanto que ele lança uma Exception, que significa exceção.
Exceções podem ser tratadas em código, mas as vezes elas não podem ser tratadas o que implica a finalização da execução. Ao se lançar uma exception, a JVM vai criar uma estrutura que contem o contexto da execução que chamamos de Stacktrace.
Para entender o que é uma Stacktrace, é preciso entender como um programa lida com contextos. Quando executamos um bloco de código é criado uma posição no topo da pilha de execução (stack é pilha em inglês). Ao terminar esse bloco, essa posição é removida da pilha. Vamos olhar o programa abaixo:
public class StacktraceHelloWorld {
private static void m1(int x) {
if (x % 2 == 0 && x > 100) {
throw new RuntimeException("Primeiro número impar depois de 100");
}
m2(x + new Random().nextInt(2));
}
private static void m2(int j) {
if (j % 2 == 0 && j > 100) {
throw new RuntimeException("Primeiro número par depois de 100");
}
m1(j + new Random().nextInt(2));
}
public static void main(String[] args) {
m1(0);
}
}A pilha vai ter como fundação o método main, depois ela será formada por um encadeamento de chamadas ao métodos m1 e m2. Nenhum dos elementos é removido da pilha porque os métodos nunca terminam, els ficam se chamando até que a exceção do tipo RuntimeException seja lançada.
Esse exemplo é meramente didático para mostrar como funciona o uso do throw. Mas se alterarmos o tipo de RuntimeException para apenas Exception vemos que não será possível de compilar porque há uma exceção não tratada (Unhandled exception type Exception). Isso acontece porque existem 3 tipos de exceções:
-
Error -
RuntimeException -
Exception
Error não deve ser definido em um programa. Ele será lançado quando a JVM não souber lidar com uma situação especifica, o exemplo mais comum é o OutOfMemoryError quando a JVM não conseguir alocar mais memória.
Uma RuntimeException é uma exceção que acontece em tempo de execução, mas poderia ser resolvido com pequenas validações, ou seja, é algo deveria ter sido previsto. É o que acontece quando valores nulos não são validados (NullPointerException) ou quando acontece a divisão por zero (ArithmeticException).
Os demais casos devem estender a classe Exception, mas ela adicionará uma peculiaridade ao código. Se um método não trata um Exception, ele deve declarar que lança a mesma. Isso porque ela é um resultado esperado, mas que pode ou não ser tratado em código. Um exemplo? Quando estamos lidando com conexões de rede, sempre existe a possibilidade de a conexão ser finalizada, por isso sempre temos a IOException. Essa declaração se dá usando o throws e este não pode ser ignorado. Ou a exceção é tratado no método acima ou lançada para o próximo método.
public void conecta() throws IOException {
// abre e fecha conexão
}12. Sincronizado (synchronized)
synchronized deve ser usada com muita parcimônia. Nós vamos ver o seu uso mais a fundo quando formos falar de threads. Mas sendo sucinto, ela pode ser usada tanto para métodos quanto para objetos.
Para entender o conceito de sincronia, é preciso entender o que é paralelismo e concorrência. Eu tenho duas atividades que rodam em paralelo quando elas acontecem ao mesmo tempo e não há interferência entre si. Mas elas se tornam concorrentes quando existem recursos compartilhados que não podem ser acessados ao mesmo tempo.
Difícil de entender, não? Então vamos criar um modelo real. Digamos que uma loja tenha um livro caixa que deve registrar todas as vendas. Mas esse livro caixa só é atualizado no final do dia através das anotações de cada vendedor. Assim quando o vendedor realiza uma venda, ele faz uma anotação que depois será repassada para o livro caixa. As vendas acontecem em paralelo. Mas ao finalizar a venda existe o registro do estoque que é um caderno único que registra a entrada e saída de itens do estoque. Ou seja, quando o vendedor finaliza a venda, ele deve pegar o registro do estoque e adicionar uma saída. Se o vendedor A está em posse do registro, o vendedor B precisará ficar esperando, logo a baixa no caixa são operações concorrentes.
synchronized irá definir sob qual objeto será definida a sincronia da execução. Ele pode ser usado tanto para método (estático ou de instância) ou objeto avulso.
class Concorrente {
public static synchronized void syncStaticMethod() {
// Toda execução desse método será concorrente
}
public synchronized void syncMethod() {
// Toda execução desse método será concorrente somente se for a mesma instância de Concorrente
}
public void method(Object lock) {
synchronized (lock) {
// Toda execução desse bloco será concorrente somente se a instância de lock for a mesma
}
}
}Para que a sincronia seja bem elaborada, devem ser usados também os métodos wait, notify e notifyAll. Mas nós veremos como isso deve ser feito mais a frente, caso você precise lidar com valores compartilhados, prefira usar AtomicReference ou outras classes do pacote java.util.concurrent.atomic.
13. Operadores Lógicos
Os operadores lógicos do Java são usados para se criar expressões booleanas. Uma expressão booleana só pode retornar dois tipos de valores: verdadeiro ou falso.
Como vimos no uso do if, devemos sempre definir um valor booleano, mas as vezes ele pode ser uma série de valores encadeados em uma expressão.
É muito importante saber resolver esses tipos de expressão, essa é um campo da matemática que se chama Algebra Booleana e, na minha opinião, é um dos requisitos mais básicos para desenvolvimento de software.
No Java tempos três operadores booleanos &&, || e !
| Operador | Descrição | Exemplo | Significado |
|---|---|---|---|
|
E |
|
|
|
OU |
|
|
|
Negação |
|
|
14. Operadores Binários
Operadores binários realizam operações binárias. Para entender como funcionam operações binárias é preciso entender que toda informação é armazenada em formato binário, isso significa que o número 6544 é o mesmo valor de 0b0001100110010000 e 0x1990.
| Operador | Descrição |
|---|---|
|
Translada os bits para esquerda |
|
Translada os bits para a direita |
|
Faz a operação E bit a bit |
|
Faz a operação OU bit a bit |
|
Faz a operação XOU bit a bit |
|
Inverte (complemento) os valores dos bits |
15. Operadores Matemáticos
Operadores matemáticos realizam operações matemáticas básicas.
| Operador | Descrição |
|---|---|
+ |
Operador aditivo (também usado para concatenação de String) |
- |
Operador de subtração |
* |
Operador de multiplicação |
/ |
Operador de divisão |
% |
Operador restante |
16. Operadores Unários
Operadores unários realizam operações matemáticas básicas usando uma única variável. Os operadores unários mais comuns são ++ e -- que fazem duas operações sequenciais: retornam o valor e alteram o valor da variável. A posição do operador irá influenciar na ordem das operações. Veja o código abaixo a diferença.
int x = 0; // x=0
int y = ++x; // x=1 y=1
int z = 0; // z=0
int w = z++; // z=1 w=0O operador unário pode ser usado também com expressões, mas para isso deve acompanhar o =. Veja no código abaixo.
int x = 0; // x=0
x += 10; // x=10
int y=2; // x=10 y=2
x-=y; // x=8 y=2
boolean w = true; // w=true
boolean v != x; // w=true v=false17. Cast
O cast é uma conversão. Java é uma linguagem orientada a objetos, por isso todo valor estende a classe Object, mas todo valor tem uma própria classe. Usamos o cast em duas situações distintas, quando vamos lidar com classes mais especificas ou quando precisamos mudar o tipo de números.
O primeiro caso vamos ver mais a frente, já o segundo é quando precisamos alterar um tipo de valor para calculo matemático.
float x = 1.23121f;
int y = ((int) (x * 100.0f)) / 2;
System.out.println("x= " + x + " y=" + y); // x= 1.23121 y=6118. Operador condicional
O operador condicional é como se fosse um if em uma só linha. Ele é composto de uma expressão booleana e dois blocos que devem retornar um valor.
Vamos supor que precisamos calcular o valor absoluto de um número inteiro, isso pode ser feito com uma linha só.
void int abs(int valor) {
return valor > 0 ? valor : -valor;
}Exercícios
Os exercícios são propostos como forma de validar que você pode ir para o próximo passo. Para fixar o conteúdo dessa sessão implemente alguns algoritmos básicos como:
-
Implemente a área do círculo
-
Implemente o calculo da média aritmética
-
Implemente o calculo da mediana
Para implementar os exercícios procure por // [EXERCÍCIO][CAP 02], implemente e execute mvn clean test para validar.
A biblioteca Collections
No post anterior nós falamos sobre o que é a JVM e sobre como criar seu primeiro projeto Java. Se você não leu e não sabe escrever um código Java, volta aí no post anterior e veja.
Agora vamos dar um segundo passo, pois para quem está começando a entender Java uma das dificuldades é conhecer a extensa biblioteca que a JVM provê. Essa biblioteca trás para nos dá a capacidade de não reescrever códigos básicos para qualquer software, por isso não conhecer é um risco, pois podemos precisar reescrever código que já estão a nossa disposição. Precisamos também compreender alguns conceitos para usar bem os recursos a nossa disposição, vou dar um exemplo fora do contexto desse post, ninguém precisa implementa uma conexão socket, basta usar a classe java.net.Socket.
Na figura abaixo, temos a lista de todos os módulos da versão 17 do Java (uma versão é chamada de JDK, Java Development Kit). É essencial conhecermos o módulo java.base, já os demais módulos podem ser necessários para funcionalidades específica.
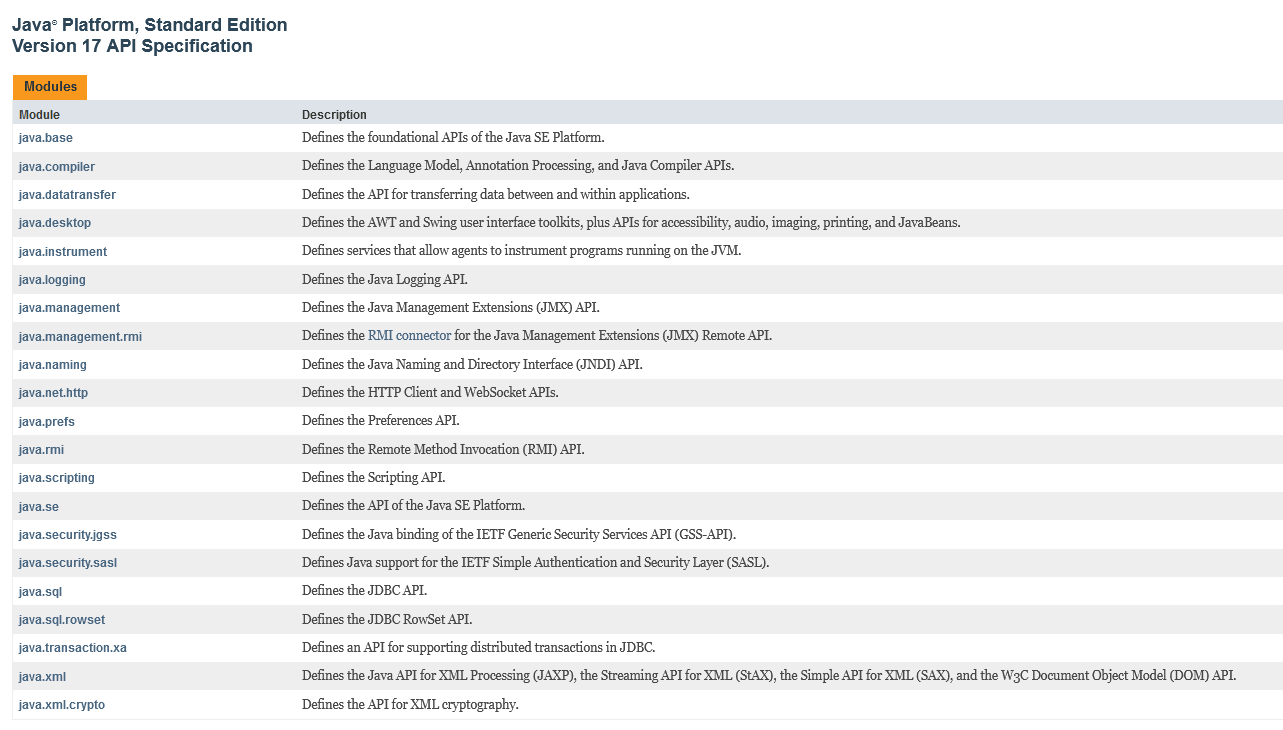
— Tem muita biblioteca aí! Pode onde devo começar?
Eu recomendaria pelo que conhecemos como Collections. Ela não é especificamente um pacote, mas uma interface, a Collection, e uma série de classes que a usam. A Collections é praticamente onipresente em todo código Java.
Quando ouvimos falar das Java Collections, podemos assumir que estamos falando de classes da biblioteca padrão do Java que estendem a interface Collection, essa interface por sua vez irá implementar uma serie de métodos que são comuns em todas as classes que implementam ela. Mas ter métodos em comum não implica em comportamento similar. Para entender o comportamento, precisamo olhar para interfaces que estendem a interface Collection, as principais são List e Set.
Mas a biblioteca Collections não está restrita a interface Collection, outras interfaces podem ser incluídas como a Map e a Stream.
Vamos olhar como usar cada uma dessas interfaces e classes? No diagrama abaixo estão listadas as classes mais importantes, exceto a Stream da qual discutiremos no final.

Listas, Conjuntos e Mapas
Listas, Conjuntos e Mapas são os conceitos básicos da biblioteca Collections. Esses conceitos podem ser abstratos a primeira vista, mas a diferença é percebida quando perguntamos o que indexa cada um deles.
Se você não entendeu o significado de indexar (indexação), podemos assumir que estou falando da forma como os elementos são agrupados. Vamos pensar uma lista (List), nela os elementos são agrupados de forma sequencial, ou seja, indexados pela posição. Mas quando temos um conjuntos (Set), eles estão agrupados pela identidade própria deles, ou seja, elementos iguais não devem ser repetidos, sendo contado apenas uma vez. Já nos Mapas (Map), os elementos são indexados por uma chave externa a própria natureza do elemento, nesse caso podemos afirmar que temos um par de chave/valor. É por isso que List e Set estendem a interface Collection enquanto Map não estende, porque essa classe não é apenas uma coleção, mas uma indexação composta por dois valores.
— Cara, você falou um monte aí, mas eu não entendi nada!
OK! Então vamos demonstrar isso por código? No pequeno trecho abaixo estou inicializando uma lista, um conjunto e um mapa e usando eles para adicionar alguns valores. Você pode ser por exemplo Strings, tente executar o código abaixo usando a ferramenta jshell (ferramenta REPL excelente adicionada na JDK 9), preste bem atenção no trecho de código a esquerda e no resultado a direta ($x representa o resultado retornado pela operação).
import java.util.ArrayList;
import java.util.HashSet;
import java.util.HashMap;
var lista = new ArrayList<String>(); // lista ==> []
lista.add("Valor 1"); // $5 ==> true
lista.add("Valor 2"); // $6 ==> true
lista.add("Valor 1"); // $7 ==> true
lista.size() == 3 // $8 ==> true
lista; // lista ==> [Valor 1, Valor 2, Valor 1]
var conjunto = new HashSet<String>(); // conjunto ==> []
conjunto.add("Valor 1"); // $11 ==> true
conjunto.add("Valor 2"); // $12 ==> true
conjunto.add("Valor 1"); // $13 ==> false
conjunto; // conjunto ==> [Valor 1, Valor 2]
var mapa = new HashMap<Integer, String>(); // mapa ==> {}
mapa.put(1, "Valor 1"); // $16 ==> null
mapa.put(2, "Valor 2"); // $17 ==> null
mapa.put(3, "Valor 1"); // $18 ==> null
mapa.put(1, "Valor 3"); // $19 ==> "Valor 1"
mapa; // mapa ==> {1=Valor 3, 2=Valor 2, 3=Valor 1}Dá pra ver claramente que em uma List podemos adicionar (add) elementos repetidos, mas ao adicionar um elemento repetido em um Set ele não é alterado. Apesar de nosso exemplo manter a ordem, um Set não garante a ordem dos elementos. Observe também que quando adicionamos um elemento em um Set o método add irá retornar se o valor já existia ou não no conjunto.
Para um Map temos o comportamento um pouco diferente. Temos que usar a operação put com uma chave e um valor como parâmetros. Valores repetidos podem ser adicionados desde que com chaves diferentes, mas quando reutilizamos uma chave, o antigo valor associado a ele é o retorno da operação.
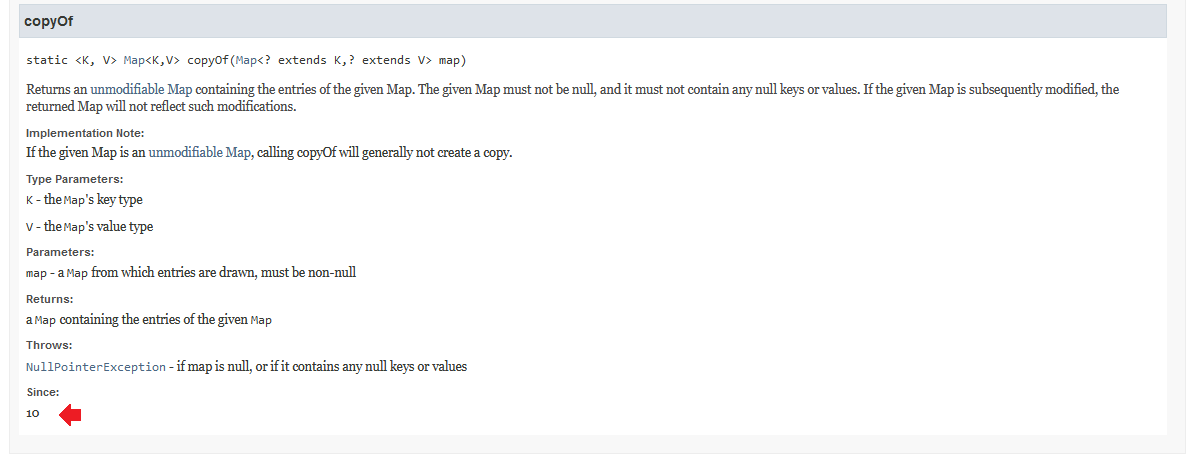
Essas três classes são muito usadas e por isso é bom conhecer cada método dela. Recomendo ler o Javadoc mesmo que você não saiba ler em inglês, tente usar o Google Translator. Você deve ficar atento é a versão da documentação que você está lendo. Cada método e classe terá uma referência sobre a versão do Java na qual ela foi introduzida. Por exemplo, abaixo tempos o método Map#copyOf) que foi introduzida na JDK 9.
Tipos de Listas
Como falamos anteriormente, listas servem para armazenar objetos sequencialmente. No nosso exemplo, usamos a class ArrayList, mas ela não é a única classe de lista existente, temos também a LinkedList. Vamos ver a diferença das duas?
Para compreender bem a diferença das duas classes, precisamos conhecer um pouco de como elas são implementadas.
A classe ArrayList é uma abstração de uma lista sobre um vetor. A classe é inicializada, por padrão, alocando um vetor de tamanho 10. Esse tamanho só será alterado quando a capacidade máxima dela for atingida, o que significa que a operação add pode significar que um vetor inteiro foi criado com o tamanho n + 1 e depois todos os elementos foram copiados para o novo vetor.
— Isso não me parece uma boa coisa…
Exato! Se a classe é utilizada para uma lista que removemos e adicionamos elementos constantemente, ela terá uma péssima performance. Quando adicionamos um elemento, no melhor caso é uma operação de tempo constante, mas no pior caso pode ser que o tempo dessa operação dependa do tamanho da lista (aqui tem o conceito de Análise assintótica que vamos falar em outro post). Já para se remover um elemento é preciso copiar todos os elementos posteriores a posição do elemento removido, o que significa que essa operação só é ótima quando removemos o último elemento.
— Então a classe ArrayList é péssima!
Não! Nós só falamos as desvantagens dessa classe! Ela é a classe do Java Collection mais utilizada, pois ela é ótima quando você tem uma lista de acesso aleatório.
— Que raios é acesso aleatório?!?!
Acesso aleatório é quando você precisa acessar um elemento qualquer da lista sem nenhuma ordenação. Digamos que você deseja acessar a posição 541 de uma lista com 9172 elementos, o tempo de acesso é constante. O mesmo acontece se você precisa substituir um elemento dentro da lista.
Logo, essa classe é ótima para listas de tamanhos fixos (ou com pouca variação) e que precise de acesso aleatório. Se você já sabe o tamanho da lista que irá preencher, você pode já iniciar a classe com o tamanho deseja, isso vai poupar muito processamento do seu software!
A outra classe é a LinkedList, ela é bem mais complexa que a ArrayList. Se você abrir o código dela, vai ver que a classe só armazena o primeiro elemento, o último elemento e o tamanho da lista. Cada elemento é um nó da lista, que contém uma referência ao elemento posterior e anterior. Isso significa que para acessar um elemento, é preciso navegar na lista pelos nós.
— OI?!?!
Vamos demonstrar… Se tivermos uma lista com 10 elementos, e eu preciso acessar o elemento na 5ͣ a operação vai acessar os elementos 1, 2, 3, 4 e depois retornar o 5. Isso significa que qualquer operação que não seja na cabeça ou na calda da lista vai depender da posição do elemento.
— Então ela não serve para acesso aleatórios como a ArrayList?!?
Servir ela serve… Devemos usar a palavra ótimo! Ótimo é um conceito que sempre associamos a algo bom, mas na verdade ótimo é quando atingimos uma situação satisfatória de acordo com certos parâmetros. Servir não é um termo correto porque independente do uso as duas classes vão responder corretamente, mas se considerarmos o parâmetro velocidade, podemos escolher uma implementação de lista ótima.
Mas voltando a resposta… A LinkedList é ótima para usos em que elementos são adicionados/removidos no inicio e no final constantemente. É por esse motivo que a classe implementa duas interfaces que adicionam métodos importantes para o acesso direto desses elementos, a Queue e Deque.
Por fim podemos falar da PriorityQueue… Essa classe é especial porque ela pode funcionar como uma lista comum, mas podemos associar ela a um Comparator que irá definir a prioridade que os elementos devem ser acessados. Internamente os elementos são armazenados pela ordem de inserção, mas eles são retornados pelos métodos poll() de acordo com a ordem estabelecida pelo comparador usado no construtor, isso significa que você sempre inicializar com um comparador.
Vamos ver ela em execução? No exemplo abaixo vamos adicionar algumas Strings e ver como elas são retornadas pelo método poll().
var lista = new PriorityQueue<String>(); // lista ==> []
lista.add("a"); // $2 ==> true
lista.add("d"); // $3 ==> true
lista; // lista ==> [a, d]
lista.add("b"); // $5 ==> true
lista; // lista ==> [a, d, b]
lista.add("d"); // $7 ==> true
lista; // lista ==> [a, d, b, d]
lista.poll(); // $9 ==> "a"
lista.poll(); // $10 ==> "b"
lista.poll(); // $11 ==> "d"
lista.poll(); // $12 ==> "b"Observe que existe uma ordenação no retorno, tanto que a falta de ordem na adição foi resolvida. Essa classe é muito útil quando precisamos implementar uma lista de prioridades.
Tipos de Conjuntos
Os conjuntos são mais simples que as Listas, vamos ter duas classes importantes: HashSet e TreeSet.
HashSet deve ser usada quando a ordem dos elementos não é importante, tanto que a interface não dispõe de métodos para acesso sequencial aos elementos. Os elementos são tratados como um conjunto. Se você for abrir a implementação do HashSet, ela usa um HashMap internamente, a seguir veremos como o HashMap funciona. A adição/remoção em um HashSet são mais rápidas que em uma TreeSet.
Já a TreeSet é um conjunto ordenado, por isso existe a necessidade de um Comparator, isso significa que os elementos podem ser acessados em ordem, mas ao se adicionar há uma penalidade pois haverá uma operação de balanceamento da árvore interna.
Em resumo, use HashSet se a ordem não importa e TreeSet se a ordem importa!
Tipos de Mapas
Os mapas são a base de implementação dos conjuntos, HashMap terá o mesmo comportamento do HashSet exceto pelo fato de que ao invés de indexar pelo próprio elemento, ele será indexado pela chave. Já o TreeMap vai armazenar os elementos seguindo a ordenação das chaves.
Streams
Stream é uma interface pela qual teremos um post especifico futuramente pois essa foi uma das maiores contribuições do Java 8. Quando usamos o método stream() presente em cada Collection, nós não criamos uma nova coleção, nós apenas iniciamos o processo de criação de uma pipeline. O principal conceito de um Stream é que a construção da nova collection será postergada até que o final dela seja conhecido. Essa propriedade é o que chamamos de Lazy Evaluation, isso significa que existirá um algoritmo para criação dessa lista, mas ele só será executado ao final.
— Entendi bulhufas!
OK! Vamos demonstrar usando o JShell…
var lista = Arrays.asList("a", "aaa", "b", "c", "aaaaa", "asdada"); // lista ==> [a, aaa, b, c, aaaaa, asdada]
lista.stream().filter(x -> x.contains("a")).collect(Collectors.toList()); // $2 ==> [a, aaa, aaaaa, asdada]No código acima nós criamos uma lista e depois criamos um Stream baseado nela. Até chamar o método collect, o Stream não passava de uma sequência de operações sob a lista, depois se cria uma nova lista (poderia ser qualquer coisa) usando as operações. A lista original não é alterada!
Conclusão
Collections é uma biblioteca onipresente! Em qualquer código você verá vestígio dela. Experimente e conheça.
Orientação a Objetos
Java tem um fã clube enorme! São pessoas que usam a linguagem no dia a dia e resolvem problemas importantes para a nossa sociedade. Quando Java completou 25 anos houve até a hashtag #MovedByJava para mostrar que o mundo é movido por software desenvolvido em Java, são bilhões de transações em Java em serviços altamente escaláveis.
MAS… existe um pequeno grupo raivoso e ruidoso que odeia Java. Eu não desejaria nem citar esse grupo, mas creio que isso tem que estar em qualquer tutorial de Java, não para dar voz a esse povo, mas para desmentir. Java não é lento, talvez você que não está sabendo usar e vamos mais a frente falar sobre tuning. Essas pessoas usam argumentos bem simples como "tudo tem que estar em objetos", "eu tenho que escrever um main dentro de um objeto", "nada disso faz sentido"… Resolvi citar eles aqui, porque eles não odeiam Java, eles odeiam Orientação a Objetos e com esse post eu vou te convencer que além de ser uma ótima forma de pensar, Orientação a Objetos ajudou a pavimentar os outros paradigmas que estão por aqui no ano de 2022.
Um pouco de história
Orientação a Objetos surgiu nos anos 60 e era usado para fazer simulações no Simula 67. Esta linguagem, por sua vez, acabou por influenciar o C (1979), que na verdade é uma tentativa de adicionar objetos a linguagem C. Por muitos anos o C foi uma das linguagens mais influentes do mercado, ela não era, puramente, uma linguagem orientada a objetos, era até possível intercalar código C com código C++. A primeira linguagem que surge como puramente orientada a objetos e ainda por cima compilada em bytecode para ser executado em uma Máquina Virtual foi…
PAUSA DRAMÁTICA… 🥶
O Smalltalk! O que foi? 🧐 Achou que era o Java? O Java só surge em 1991, e em seu lançamento em 1995, e acaba herdando muitas características do Smalltalk, tanto que muitas pessoas da comunidade Java vieram do mundo Smalltalk. E uma das coisas que Java herda é ser primariamente orientada a objetos.
— Mas porque essa preocupação em ser Orientada a Objetos?!
Porque na verdade a computação não começou com essas linguagens e nem com esses paradigmas, mas como Programação Funcional (ver Conception, evolution, and application of functional programming languages). Linguagens funcionais são excelentes para modelarem problemas matemáticos e alguns problemas computacionais, pois elas são declarativas. Podemos transpor a definição de um problema para a linguagem de programação facilmente, podendo até mesmo aplicar uma lógica equacional, pois, se as funções são puras, o valor de f(x) só precisa ser calculado uma vez. Logica equacional é o mesmo que tratar uma função como uma equação matemática, isso implica que símbolos iguais terão valores iguais.
MAS linguagens funcionais apresentam uma certa dificuldade de modelar alguns tipos de sistemas e, com a popularização da computação, foi necessário outros paradigmas para os novos sistemas que foram sendo desenvolvidos. O primeiro desses paradigmas foi a Programação Procedural, popularizado pela linguagens como C. Nesse tipo de linguagem a lógica de programação pode ser estruturada dentro de procedimentos que podem ser tanto funções quanto procedimentos, a diferença entre os dois é que uma função não altera o valor dos parâmetros e sempre retorna um valor, já os procedimentos alteram o valor dos parâmetros e não retornam nenhum valor. Em C, podemos escrever tanto funções quanto procedimentos.
Linguagens procedurais apresentam bastante dificuldade para encapsular complexidade porque é difícil criar abstrações com ela. Em C, os dados são sempre modelados usando tipos primitivos ou estruturas, que nada mais são que agrupamentos de tipos primitivos. Mesmo quem desenvolve C hoje em dia, não consegue compreender o que era desenvolver nos anos 70, pois a linguagem continuou avançando. Eu tenho uma leve ideia porque, na universidade, desenvolvi programas para um microcontrolador com o compilador bem limitado. O exemplo abaixo eu retirei de um visualizador de CSV que eu desenvolvi por necessidade.
matrix_config_t *matrix_config_initialize(size_t width, size_t height)
{
matrix_config_t *config = (matrix_config_t *)malloc(sizeof(matrix_config_t));
config->columns = width;
config->heights = height;
config->column_width = (size_t *)calloc(width, sizeof(size_t));
config->line_height = (size_t *)calloc(height, sizeof(size_t));
return config;
}Observe que no código há a preocupação de se alocar a posição de memória necessária para uma determinada estrutura chamada matriz_config_t e que essa alocação é feita através de duas funções diferentes calloc e malloc. Esse código pode parecer simples, mas tem diversidades camadas de complexidades, como simplesmente diferenciar essas duas funções.
— Aonde você quer chegar?!?!
Ora! Qual é o objetivo de um desenvolvedor?
— Escrever código!
Errado! O objetivo de um desenvolvedor é resolver problemas através da escrita de código. Por isso, desenvolvedores não podem e não devem ficar preocupado com complexidades desnecessária. É para remover essa complexidade que surgem linguagens Orientadas a Objetos. As linguagens procedurais são simples e com poucas funcionalidades, por isso toda a informação é armazenada de forma simplória em estruturas. Isso gera complexidade e o objetivo principal de uma linguagem de programação é encapsular complexidade.
Vamos tentar explicar de outra forma…
O que é Programação Orientada a Objetos
Vamos estabelecer algumas hipóteses….
E se eu puder lidar com tipos complexos
Uma linguagem OO irá sempre lidar com tipos de dados cada vez mais complexos pois não estamos apenas falando de programação, mas de encapsulamento de complexidades.
Vamos supor que eu desejo desenvolver uma API para navegação robótica e eu sei que meu robô tem 4 rodas e que posso definir a velocidade de cada roda. Será que eu preciso saber qual é a velocidade de cada roda? Ou eu posso apenas mandar comandos para o meu robô? Um exemplo de comandos são: "Vá para frente", "Faça uma curva de 30º", "Pare".
Quando falamos de Orientação a Objetos, devemos pensar em design de código. Não estamos falando de programação pura, mas de uma modelagem de dados e conceitos. Os detalhes internos devem ser escondidos para quem só sejam visíveis para os próprios times de manutenção.
E se eu puder associar comportamento aos meus tipos complexos
Todo código tem um contexto para ser executado. Quando eu tenho um robô e eu desejo que ele vá para uma posição, se essa ordem é diferente para cada robô e produz diferentes resultados, mas ela sempre está associada a um robô, ou seja, não faz sentido um outro objeto que não seja um robô se mover (ainda falarei de herança).
Mas podem existir outros objetos que se movem, certo? E como fica se a função mover é somente associada a robôs?
Em uma linguagem orientada a objetos, não temos funções e nem procedimentos, mas métodos. A diferença é que uma função transforma dados, procedimentos executa uma série de alterações nos parâmetros, mas um método envia uma mensagem (essas definições não tem caráter acadêmico, se alguém tiver alguma referência me manda no Twitter). Logo um método vai pertencer a um objeto, assim se formos modelar um Avião, podemos criar um outro método mover que existirá somente para um Avião e que será diferente do método mover de um robô.
E se puder compartilhar o comportamento entre tipos diferentes
Objetos tem um tipo especifico, por exemplo nós estamos falando de um robô. Mas eu posso assumir que um robô é um tipo de objeto móvel? Posso eu criar métodos nesse objeto móvel? O que essa implementação desse método faz para um robô é a mesma coisa que se faz para um avião?
Para cada pergunta acima, existe uma resposta no mundo da Programação Orientada a Objetos e é o que vamos ver na próxima sessão.
Orientação a Objetos
Nós falamos um pouco sobre Programação Funcional e Programação Procedural, então vamos definir o que é Programação Orientada a Objetos (POO) antes de ver como Java faz POO.
Programação Orientada a Objetos é um modelo de design, analise e desenvolvimento de software que organiza todo o software ao redor dos dados e suas abstrações. Para que isso seja possível, é criado o conceito de Objeto. Um objeto é um componente de software composto de atributos e comportamento.
Quando falamos de orientação a objeto, focamos na definição do que é um objeto e das operações que esse objeto pode realizar, ao contrário da lógica necessária para realizar a operação. Os principais benefícios da POO é a reutilização de código, escalabilidade e eficiência no desenvolvimento. Então podemos definir que POO vai ter alguns elementos.
Elementos
Abaixo vemos as descrições de cada elemento da POO, elas não se referem a linguagem Java, mas ao paradigma em si.
Classes
Classes são tipos de dados definidos pelo usuário que atuam como modelo para objetos, atributos e métodos.
Objetos
Objetos são instâncias de uma classe criada com dados específicos.
Métodos
Métodos são funções definidas dentro de uma classe que descrevem o comportamento de um objeto. Cada método contido nas definições de classe começa com uma referência a um objeto de instância. Além disso, as sub-rotinas contidas em um objeto são chamadas de métodos de instância. Os programadores usam métodos para reutilização ou para manter a funcionalidade encapsulada dentro de um objeto por vez.
Atributos
Atributos são definidos no modelo de classe e representam o estado de um objeto. Os objetos terão dados armazenados no campo de atributos. Os atributos de classe pertencem à própria classe.
Princípios
Quando falamos em Orientação a Objetos, temos em mente alguns princípios.
Encapsulamento
Encapsulamento significa que um objeto não é obrigado a expor a sua implementação e nem os seus atributos. Cabe ao design do objeto escolher como será feita essa exposição. Essa característica de ocultação de dados fornece maior segurança ao programa e evita corrupção de dados não intencional.
Abstração
Objetos criam abstrações que tornam possível controlar a complexidade. Ao se criar uma classe, o restante do sistema deverá interagir através da interface que ela propõe não tendo acesso a sua lógica interna.
Herança
As classes podem reutilizar o código de outras classes. Relacionamentos e subclasses entre objetos podem ser atribuídos, permitindo que os desenvolvedores reutilizem a lógica comum enquanto ainda mantêm uma hierarquia única. Essa propriedade da OOP força uma análise de dados mais completa, reduz o tempo de desenvolvimento e garante um maior nível de precisão.
Polimorfismo
Os objetos são projetados para compartilhar comportamentos e podem assumir mais de uma forma. O sistema poderá definir como vê um objeto e como interage por ele baseado na sua própria classe ou em alguma classe pai, reduzindo a complexidade ou a necessidade de duplicar código. Quando uma classe filha é criada, que estende a funcionalidade da classe pai, ambas podem ser tratada pelo mesmo código usando a classe pai como interface. O polimorfismo permite que diferentes tipos de objetos usem a mesma interface.
Como Java faz Programação Orientada a Objetos
Java é uma linguagem primariamente orientada a objetos, logo você deve primeiro entender o que é uma classe. Classe é o arquétipo de um objeto. Arquétipo, resumidamente, é o tipo comum de algo. Por exemplo, se eu falar que existe o tipo Gato, você vai imaginar o formato desse animal e algumas outras características, mas se eu falar que existe o Garfield você vai imaginar que ele é um Gato laranja, gordo e preguiçoso. O Garfield é um indivíduo do arquétipo Gato.
Vamos transpor isso pra Java? Podemos ter uma classe Gato, mas o objeto será um Garfield. Assim, podemos ter…
package org.animais.mamiferos;
import org.fisica.luz.Cor;
import org.animais.psique.Temperamento;
public class Gato {
private float pesoEmKg;
private final Cor cor;
private Temperamento temperamento;
public Gato(float pesoEmKg, Cor cor, Temperamento temperamento) {
this.pesoEmKg = pesoEmKg;
this.cor = cor;
this.temperamento = temperamento;
}
// MÉTODOS
}Isso significa que podemos modelar qualquer Gato por esse modelo, assim se quisermos ter um Garfield…
Gato garfield = new Gato(15.0, Cor.LARANJA, Temperamento.PREGUICOSO);No primeiro trecho de código tempo a declaração da classe Gato no pacote org.animais.mamiferos. Isso significa que só pode existir um tipo de Gato nesse pacote, mas isso não implica que eu possa criar o tipo Gato para descrever, por exemplo, instalações elétricas não-oficiais, que obviamente não fazem parte do pacote org.animais.mamiferos, mas org.humanos.civilizacoes.brasil.infraestrutura. Classe é usada para definir o tipo do objeto, mas o pacote é o contexto na qual ele existe. Classe e Pacote tem uma relação umbilical, uma Classe sempre deve estar ligada a um Pacote.
A segunda coisa que vamos detalhar nesse trecho de código são os modificadores de acesso. Como disse uma linguagem orientada a objetos é usada para se encapsular detalhes, logo os modificadores de acesso servem para definir quem pode acessar o quê. Eles podem ser aplicados para Classes, Métodos e Campos e existem os seguintes modificadores de acesso.
| Tipo | Token | Descrição |
|---|---|---|
Package Private |
- |
Define que o elemento será acessível dentro do pacote. Esse é o modificador padrão, isso significa que nesse caso pode ser omitido. |
Privado |
|
Define que o elemento só pode ser acessado dentro da própria classe. |
Protegido |
|
Define que o elemento é acessível dentro do mesmo pacote ou através de herança. |
Público |
|
Define que o elemento é acessível em qualquer contexto. |
Final |
|
Se aplicada a classe, ela não poderá ser estendida. Se aplicada a um campo ele não poderá ter seu valor alterado. Se aplicado a um método, ele não poderá ser reimplementado em uma classe que herda ele. |
Estático |
|
Pode ser usado tanto em campos como em classes internas. Se usado no campo, ele vai ter apenas um valor e está associado a classe. Campos não estáticos são associados a objetos. Se aplicado a classes internas, ela não dependerá de um objeto. |
Ainda existem dois mais dois modificadores (volatile e transiente), mas eles não são importantes quando falamos de OO. transiente será importante quando falarmos de serialização e volatile quando falarmos de threads. Dos outros, podemos agrupar o private, protected, public e a ausência de um desses, pois eles são mutualmente excludentes.
O próximo ponto que podemos falar é sobre métodos. Em Java não é comum termos funções puras, nem linguagem está preparada para isso. Temos basicamente dois tipos de métodos. Os métodos de instância são aqueles que são associados a um objeto. E os métodos estáticos são aqueles associados a uma classe, sem depender de uma instância. Conseguimos criar métodos estáticos usando o modificador de acesso static. Quando um método não é estático, podemos usar this para se referir a instância com a qual o método é associado.
Métodos sempre tem parâmetros e valor de retorno (pode ser void que significa um vazio existencial, diferente do vazio de posição que é a palavra empty). Métodos de instância sempre vão te acesso a um objeto específico (usando o this), enquanto métodos estáticos não o são.
Vamos ver melhor como os métodos funcionam? E se nós criássemos 3 métodos na nossa classe gato. O primeiro seria um método para mesclar características de 2 gatos, o segundo seria o método meow e o terceiro o método de reprodução (cruza).
public class Gato {
public static Gato mistura(Gato gatoA, Gato gatoB) {
// Mágica acontece
return gatoC;
}
// Campos, construtores, getters e setters
public void meow() {
System.out.println("Miau!");
}
public Gato cruza(Felino outro) {
if ((!(outro instanceof Gato)) || sexo == outro.sexo) {
throw new CruzamentoException("Não é possível gerar filhote!");
}
return mistura(this, outro);
}
}O método meow é o exemplo clássico que veremos em herança, ele não retorna nada, só executa uma ação. Aqui vamos focar nos métodos cruza e mistura (ok, focar na parte reprodutiva foi péssimo… mas estou falando de gatos!). mistura é um método que aleatoriamente vai gerar um novo gato baseado nas características de dois gatos. Nele podemos ver que o método recebe dois parâmetros e retorna um valor. No caso desse método, estamos retornando um novo objeto, mas nada impede de o retorno ser um dos parâmetros. Outra característica é que os parâmetros são uma passagem por referência e não por valor como vamos ver um pouco mais a frente. Sobre o método cruza, nele podemos acessar os campos do objeto local e campos da referência. Quero ressaltar o uso do this que é a forma de acessar a referência ao objeto pela qual o método é referenciado, o this não pode ser usado para métodos estáticos.
Como Java implementa Herança
Falamos sobre classes e alguns detalhes, mas agora precisamos falar de herança.
Temos 3 tipos de classe: a Classe, a Interface e a Classe Abstrata.
— Peraê! Mas como uma classe pode ser também Interface e Classe Abstrata?!?!? Tem algum erro lógico nessa afirmação!
Não! Segura essa informação que quando formos falar sobre Reflexão trataremos do conceito interno de Classe. Por enquanto aceite que existem três tipos de classe e um deles é classe. 🤷♂️
A Interface é quando tempos um contrato de como uma classe deve ser implementada. Ela vai definir a assinatura de alguns métodos. Por assinatura entenda que é a forma como a JVM usa para identificar um método, ela é composta pelo nome do método e a lista de parâmetros. O tipo de retorno não faz parte de uma assinatura e isso vai ser importante mais a frente. Uma interface também pode definir métodos default e métodos static. Uma interface normalmente é usada para definir um tipo, ou comportamento, comum dentro de um sistema.
Uma classe abstrata é uma classe que não pode ser instanciada. Normalmente usamos quase abstrata quando desejamos compartilhar comportamento entre vários tipos. Em uma classe abstrata podemos definir variáveis e métodos, mas também podemos definir métodos abstratos (usando o modificador abstract). Ao se declara um método abstrato, estamos declarando apenas a assinatura, a implementação ficará a cargo de alguma classe que estende nossa classe abstrata.
E por fim uma classe é uma implementação pela qual podemos instanciar objetos. Classes podem ser estendidas também quando queremos modificar um comportamento específico. Por exemplo, e se quisermos modificar a forma como o Garfield mia?
Gato garfield = new Gato(15.0, Cor.LARANJA, Temperamento.PREGUICOSO) {
public void meow() {
System.out.println("Miaaaaaaau!");
}
};Quando adicionamos um bloco de código lodo após a instanciação da classe, estamos criando uma classe anônima. Esse comportamento será especifico dessa instância. Nós poderíamos evitar isso usando o modificador final no método ou na classe. Se usarmos no método, nenhuma subclasse poderá estender esse método, mas se usarmos na classe, ela não poderá ser estendida.
Quando falamos de herança normalmente usamos as palavras estende e implementa. Estende é quando temos uma classe abstrata sendo estendida, e isso é feito usando a palavra reservada extends. Já implementa é quando temos uma interface sendo implementada pela classe, a palavra reservada implements.
O Java tem algumas limitações em heranças. Uma classe SÓ pode estender uma classe, mas pode implementar quantas interfaces forem necessárias. MAS interfaces com mesma assinatura e tipo de retorno diferentes não são possíveis de serem implementas por uma mesma classe. No caso abaixo, temos que um Gato estende um Felino e implementa as interfaces Miador e Ronronador.
public class Gato extends Felino implements Miador, Ronronador {
// Implementação
}Conceitos da Orientação a Objetos
Agora vamos discutir alguns conceitos comuns da orientação a objetos que podem nos auxiliar no dia a dia.
Herança
Para entender herança, podemos pensar em herança genética. Todo objeto ele tem um arquétipo e ele vai possuir uma hierarquia de tipos. Um Gato é um Felino que é um Animal. Cada uma dessas classes podem ter comportamentos associados ou apenas assinaturas de métodos. Se voltarmos no post anterior, sobre a biblioteca Collections, vamos ver o mais comum tipo de herança.
Vamos ver o caso da LinkedList que estende uma AbstractSequentialList e implementa as interface List, Deque, Cloneable e Serializable.
LinkedList é uma classe, AbstractSequentialList é uma classe abstrata e List uma interface. AbstractSequentialList contém uma implementação de lista que por sua vêz estende uma AbstractList. Podemos dizer que LinkedList herda implementações de AbstractSequentialList e AbstractList. Assim como podemos dizer que LinkedList e ArrayList herdam implementações de AbstractList mesmo tendo comportamentos completamente diferentes.
Da mesma forma LinkedList e ArrayList são tipos de List, enquanto apenas LinkedList é um tipo de Deque.
Quando temos uma classe que herda tipos de outras classe, podemos definir nossos objetos com o tipo que desejarmos. Eu recomendo sempre usar a interface que você deseja usar e não a implementação final. Quer um exemplo? Vamos imaginar que eu quero definir um método que fará uma busca especifica pelo Gato mais gordo. Ao invés de declarar que desejo receber uma LinkedList, posso declarar que desejo receber apenas uma List.
public class Gatos {
public static Gato maisGordo(List<Gato> gatos) {
// encontra o Garfield aqui que não tem erro.
}
}Uma dúvida clássica é se perguntar porque não devo usar o tipo mais específico. Nunca devemos usar as classes porque isso limita o uso do nosso código. Ao usar um List, eu posso aceitar qualquer implementação de List, mesmo implementações que eu não conheço. Essa preocupação será muito mais real quando estivermos falando de frameworks em que a geração de código ou classes do tipo proxy são comuns.
Override
Chamamos de Override a prática de sobrescrever implementações de métodos em classes filhos. Vamos voltar ao nosso exemplo de Gatos, e se existe uma raça especifica de gatos que não mia, são gatos mudos. Como esse característica é muito especifica mas ele definitivamente são gatos, podemos criar essa nova classe de gatos e sobrescrever o método.
public class GatoMudo extends Gato {
@Override
public void meow() {
System.out.println("."); // . significa silêncio
}
}Se tivermos um objeto da classe GatoMudo, mesmo que ele esteja definido como Gato, será chamado o método da classe GatoMudo.
O uso da anotação @Override não é obrigatório, mas é altamente recomendável.
Overload
Chamamos de Overload quando criamos um novo método para um tipo diferente de parâmetros. Essa técnica é excelente quando queremos criar métodos semelhantes para tipos diferentes. Vamos supor que nosso método de mistura vai ser migrado para a classe abstrata de animais e que queremos criar esse método para alguns tipos de animais, não para todos, mas ele será diferente para alguns grupos (tem animal que se divide e não reproduz). Assim podemos criar um método mistura para os tipos Mamifero, Ave, Reptil e Peixe, cada método terá uma implementação completamente diferente.
public class Gato {
public static Mamifero mistura(Mamifero mamiferoA, Mamifero mamiferoB) {
// Mágica acontece
return mamiferoC;
}
public static Ave mistura(Ave aveA, Ave aveB) {
// Mágica acontece
return aveC;
}
public static Reptil mistura(Reptil reptilA, Reptil reptilB) {
// Mágica acontece
return reptilC;
}
public static Peixe mistura(Peixe peixeA, Peixe peixeB) {
// Mágica acontece
return peixeC;
}
}Nós fizemos overload de um método estático, mas poderíamos ter feito de um método de instância.
HashCode, Equals e ToString
Uma outra reclamação constante de quem não gosta de Java é a necessidade de se implementar esses três métodos que as vezes parecem inúteis.
Primeiro devemos esclarecer que hashCode, equals e toString são métodos extremamente úteis e usados constantemente pela JVM. É sempre recomendável a leitura da documentação da classe Object sobre esses três métodos.
hashCode é um método usado para o calculo do Hash do objeto. O hash é um valor inteiro que será usado para identificar cada objeto. Dois objetos iguais devem ter o mesmo hash, mas dois objetos com o mesmo hash não são iguais. Toda e qualquer classe usando o nome Hash usar esse método, assim se você tem um HashMap ou um HashSet, você tem o uso do método.
equals é um método usado para se verificar um objeto é igual a outro. Ele é usado por várias algoritmos da JVM, as vezes associado com o hash ou sem associação. Quando temos um HashMap os dois métodos são usados. O equals é usando quando temos o que chamamos de Colisão de Hash, dois objetos diferentes que tem o mesmo hash.
toString é usado para se criar um valor String para a classe. Sempre implemente o toString para melhorar o rastreamento de erros em logs de execução.
Passagem por valor e Passagem por referência
Quando estudamos linguagem como C, estudar o tipo de passagem como argumento de uma função é muito importante, porque é possível controlar o que queremos fazer ao se escolher o tipo de parâmetro. Já em Java não nos preocupamos muito, mas em ambas a linguagem temos a possibilidade de se passar um argumento como valor ou como referência. Vamos primeiro definir para depois mostrar como pode ser feito?
Falamos de Passagem por valor de um argumento para uma função quando ao se alterar o valor desse argumento dentro de um função, essa alteração não é refletida fora da função. Já quando falamos de Passagem por referência de um argumento, ao se alterar o valor desse argumento dentro da função ele é refletido fora da função. Fácil de entender? Não?!?!
Em C, isso é meio óbvio porque podemos passar o valor ou a referência. Vou tentar mostrar aqui:
#include <stdio.h>
int incrementaValor(int valor) {
return valor + 1;
}
int incrementaReferencia(int * valor) {
(*valor)++
return *valor;
}
int main() {
int contador = 0;
printf("Valor: %d\n", incrementaValor(contador)); // Imprime "Valor: 1"
printf("Valor: %d\n", incrementaValor(contador)); // Imprime "Valor: 1"
printf("Valor: %d\n", incrementaReferencia(&contador)); // Imprime "Valor: 1"
printf("Valor: %d\n", incrementaReferencia(&contador)); // Imprime "Valor: 2"
return 0;
}O que acontece quando eu chamo a função incrementaValor é que uma cópia do contador é enviado para a função, mas quando chamo incrementaReferencia o próprio contador é enviado para a função.
Em Java só temos passagem por valor quando usamos tipos primitivos (byte, short, int, long, float, double ou char). Quando definimos um objeto, sempre estamos passando a referência do mesmo para funções. Por isso é muito importante entender o que é e como garantir imutabilidade. Quando formos falar de memória, vou explicar o que é o conceito de memória e como isso funciona na prática, mas, resumidamente, tipos primitivos são armazenados na stack do programa enquanto todas as classes são armazenados na memoria heap do programa. Ao se criar um objeto, um ponteiro na stack é criado para um novo espaço de memoria alocado na Heap. Calma, você não tem obrigação de entender isso facilmente!!!
Imutabilidade e Mutabilidade
Chamamos de mutabilidade a capacidade de um objeto ter seu estado interno alterado. Em orientação a objetos mutabilidade é um requisito desejado para quase todas as classes, por isso que só recentemente o Java incorporou o conceito de imutabilidade a linguagem através dos Records. Antes dos Records era comum se usar POJOs em que existia para cada campo um respectivo get e um set.
Records é o tipo que adiciona o conceito de imutabilidade ao código Java. Abaixo vou definir a classe Usuario três vezes. Na primeira vez ela é mutável, na segunda imutável usando POJO e na terceira usando record.
public class Usuario {
private int id;
private String username;
private String email;
public Usuario(int id, String username, String email) {
this.id = id;
this.username = username;
this.email = email;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
// Implementa hashCode, equals e toString
}Para implementar um campo imutável, devemos usar o modificador de acesso final. Um campo final terá seu valor definido no construtor e não poderá ser alterado em todo ciclo de vida do objeto.
public class Usuario {
private final int id;
private final String username;
private final String email;
public Usuario(int id, String username, String email) {
this.id = id;
this.username = username;
this.email = email;
}
public int getId() {
return id;
}
public String getUsername() {
return username;
}
public String getEmail() {
return email;
}
// Implementa hashCode, equals e toString
}Ao usar records, é como se todos os campos já fossem definidos como final, mas a grande vantagem se dá que não precisamos implementar os métodos hashCode, equals e toString.
public record Usuario(int id, String username, String email) {}Conclusão
Orientação a Objeto é uma ótima técnica para fazer design de código. Ela é melhor utilizada quando tempos que modelar problemas do mundo real, mas haverá dificuldade se o modelo for mais próximo de um modelo matemático.
O principal ganho com a modelagem a Orientação a Objetos é a capacidade de se encapsular complexidades.
A biblioteca I/O
Esse post faz parte de uma série introdutória sobre Java, se você não conhece a linguagem e não leu os posts anteriores, recomendo os ler para ter uma visão melhor da plataforma. Nessa série, já falamos sobre o que é o ecossistema Java, o que é a biblioteca Collections e como Java faz Orientação a Objetos, esses tópicos são necessários para o que vamos falar agora: I/O.
O que é I/O?!?
Quando pensamos em um computador a primeira coisa que pensamos é no que fazemos online: enviar um tweet, responder email, ver um vídeo ou mesmo ler esse post. Mas um computador não entende essas atividades, para ele tudo são bits, ou seja, todas essa são atividades podem ser traduzidas em outras atividades de baixo nível. Quando eu uso o termo "baixo nível" entenda como algo de menor abstração, por exemplo, para você ler esse post, o seu navegador teve que renderizar uma página HTML, que foi requisitada de um servidor HTTP usando uma conexão Socket, que na verdade é apenas uma troca de bits entre vários computadores. Essas atividades sempre envolvem trocas de informações que só são possível através de algo chamado serialização.
Serialização seria a transformação de uma informação em um formato intermediário para que ela possa transitar entre dois processos. Ou seja, a informação que você está lendo agora é composta de alguns arquivos HTML, Javascript, CSS, PNG e JPEG que são enviadas através da web usando o protocolo HTTP sobre TLS.
— Você não ia falar de I/O? Que papo é esse de serialização e internet?!?
Sim, I/O é outra forma de falar sobre serialização. Toda informação para ser enviada ela passa pelos passos de (1) serialização, (2) escrita, (3) transmissão, (4) leitura e (5) desserialização. O processo de transmissão pode ser o envio dessa informação através de uma API, ou o armazenamento dela em um banco de dados ou mesmo a escrita no disco para que possa ser lida no futuro. Os formatos de serialização de dados são bem interessantes de se analisar, mas não é o foco desse post, aqui focaremos em conhecer as bibliotecas que a JVM nos oferece para que possamos ler e escrever objetos onde bem desejarmos.
Na JVM existem dois pacotes que lidam com serialização em Java. O mais conhecido deles é o java.io onde estão definidas as classes para leitura síncrona. Já no java.nio estão definidas as classes para leitura assíncrona (Non-blocking I/O).
Seria hipocrisia da minha parte dizer que você deve conhecer esses pacotes por completo, eu não os conheço. Só quem trabalha especificamente com I/O deve conhecer bem essas classes. Não se surpreenda se um desenvolvedor com anos de experiência em Java procurar no Google "how to read a text file in Java". Isso acontece porque esses pacotes são complexos e por isso difíceis de serem internalizados. Mas você deve saber algumas informações importantes e nós vamos trabalhar elas aqui.
-
Porque a interface
Serializable? Devo usar? -
O que é um
InputStreame umOutputStream? -
Qual Stream devo usar?
-
Qual a diferença entre um Stream e os Readers/Writers?
Nós não vamos falar de NIO, esse será o assunto de um post mais a frente. Não estranhe se você perceber que um Sênior não sabe como usar as classes desse pacote, em muitos casos elas são usadas apenas pelos frameworks o que implica que muitos desenvolvedores nunca tiveram contato com ela.
A diferença entre IO e NIO
Talvez você tenha ficado curioso do motivo de existirem dois pacotes para I/O. Não ficou? Bom, existem dois pacotes diferentes porque NIO é um conceito muito mais novo do que IO. IO existe desde que os computadores existem e sempre foi um problema para qualquer software. Se você não fez faculdade de Ciência da Computação, saiba que existe até uma matéria só pensando em como se criar estrutura de dados para arquivos, isso porque ao se ler um arquivos nos deparamos com alguns problemas que deveriam ser óbvios: (1) o tempo de leitura é muito inferior ao tempo de acesso a memória, (2) os dados são armazenados em blocos que não são facilmente rearranjáveis e (3) a leitura de blocos próximos é mais rápida que a leitura de blocos distantes. Os discos mais novos não possuem o problema (3), mas mesmo assim ler e escrever de arquivo não pode ser feito da mesma forma que ler e escrever na memória.
— Escrever na memória?!?! Eu nunca escrevi na memória!!!
Todo programa, ao ser executado, está armazenado na memória. Essa é uma operação tão comum que é transparente para linguagens alto nível. Se estivéssemos escrevendo em C seria preciso alocar e desalocar memória. Mas em Java a alocação é feita com um new e a memória é desalocada automaticamente. Mas não é possível alocar espaça em disco.
Se compararmos a escrita e memória com a escrita em disco, ou interface de redes, vemos que a primeira é tão rápida que pode ser considerada imediata. Já os outros tipos de escrita não podem ser consideradas imediatas, por isso surgiram uma série de interfaces capazes de avisar ao software quando o dado está pronto para ser lido. É nesse ponto que diferenciamos IO de NIO! O pacote java.io são classes usadas para leitura/escrita bloqueante, enquanto o pacote java.nio são classes de leitura/escrita não bloqueante. E como NIO é mais recente que o IO tradicional, seu pacote foi inserido em uma versão do Java bem mais recente (JDK 1.4).
Arquivos, Sockets e Linux 🐧
Uma das grandes vantagens do Sistema Operacional Linux é que tudo são arquivos. Quase todas as funcionalidades do sistema operacional são expostas através de arquivos mapeados no sistema de arquivos. Assim ao invés de fazer uma chamada de sistema complexa para, por exemplo, obter o tempo que a máquina está em operação, basta ler o arquivo /proc/uptime. Ou ler o arquivo /proc/cpuinfo para obter uma série de informações sobre a CPU.
Essa foi uma escolha arquitetural do sistema que se tornou bastante eficaz porque cria uma interface comum entre diversas operações. Por exemplo, se você for procurar no Windows a maneira de se ver todos os processo em execução, verá que tem uma API (lembre-se que API não se refere só a API REST) complexa, mas em um Linux basta executar ls /proc e todos os diretórios com números são processos. Para saber mais informações dos processos, basta acessar alguns arquivos dentro dessas pastas.
Essa informação pode parecer perdida, mas ela tem uma relação profunda com o que veremos a seguir. Quando o Linux escolhe mapear tudo como arquivo, a escolha feita é por se tratar diversas formas de dados por uma mesma interface. Arquivos são fáceis de serem lidos, então ao expor tudo como arquivo é fácil conseguir acessar essas informações. A JVM também traz a mesma abordagem! Tudo em serialização vai se resumir a poucas classes. A operação de leitura de um arquivo ou leitura de um socket são tão semelhantes que podem ser executadas pelo mesmo código.
Apresentação do pacote java.io
Para entendermos o pacote java.io primeiro precisamos entender o que é um Stream (ou fluxo em tradução livre). Não confunda Stream de I/O com Stream de Collections, eles tem um conceito parecido, mas são aplicados em locais diferentes. Stream significa fluxo e quando falamos de Stream estamos falando de uma informação que flui em sentido único.
Para entender melhor é preciso pensar em como era feito antes… As bibliotecas do C para leitura de arquivo/socket não fazem diferenciação entre as interfaces de leitura e escrita, ao se criar um canal de comunicação temos um inteiro que identifica o canal e esse inteiro pode ser usado tanto para leitura como para escrita. Observe a documentação das funções read e write e veja que elas recebem os mesmo argumentos.
Em Java foi decidido que haveria uma diferenciação lógica entre leitura e escrita. Ao se ler um arquivo poderíamos ter o fluxo de leitura (InputStream ou Reader) e o fluxo de escrita (OutputStream ou Writer). Cada um desses fluxos teria uma orientação única, isso significa que um InputStream apenas lê e o OutputStream apenas escreve. É por isso que se usa o nome Stream.
Essa é a primeira informação importante do pacote java.io: As interfaces de leitura são separadas das interfaces de escrita! Para apresentar o pacote em um diagrama de classes foi até preciso criar essa separação para possibilitar que melhor visualização.
Outro ponto da biblioteca C que explica o funcionamento do pacote java.io são as funções open e close. Em qualquer sistema operacional para se realizar a leitura em arquivo, ou em um socket, só é possível com a alocação de recurso. Isso é feito para evitar que processos diferentes criem estados inconsistentes. Quando um processo chama a função open para um determinado arquivo, ele não poderá ser aberto por outro processo enquanto não for liberado através da função close. Se a função close não for chamada, o arquivo só será liberado quando o processo morrer o que pode também gerar um estado inconsistente. Por isso era importante garantir na escrita do código que a função close sempre fosse chamada e que o arquivo sempre estivesse em um estado consistente. Lembre-se que leitura e escrita não são processos imediatos, se o programa finalizar ou o arquivo for fechado antes da escrita terminar, o arquivo fica em um estado inconsistente.

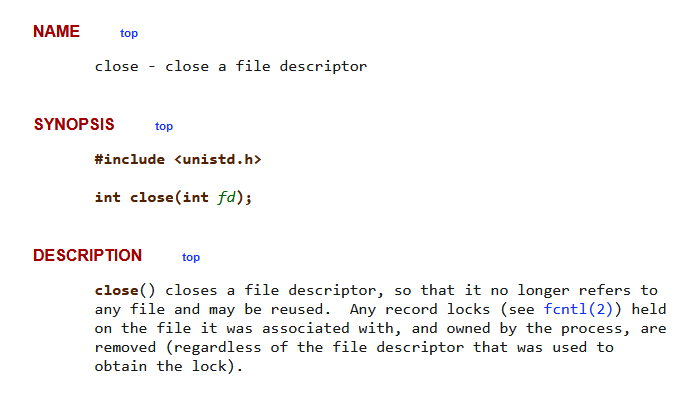
Agora volta ao Java… Em C era preciso criar mecanismos de garantir que o arquivo estava fechado antes que o programa finalizasse. Em Java isso foi internalizado na linguagem através de alguns mecanismos. Por isso temos as interfaces Closeable e AutoCloseable. Se um objeto precisa liberar recursos depois de usado, ele deve implementar a interface Closeable e o método close deve ser chamado. Até a versão 6 do Java era comum ver o close sendo chamado dentro do bloco finally de um try {} catch {} finally {}.
Reader reader = null;
try {
reader = // inicia reader
// lê dados
} catch (IOException ioe) {
// trata exceção
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException ioe) {
// trata exceção
}
}
}Como esse código tem muito boilerplate (código sem significado único, repetido), o Java 7 trouxe um recurso na sintaxe chamado try-with-resources. Agora todo inicio de um try-catch é possível declarar um ou mais objetos que devem implementar a nova interface chamada AutoCloseable. Como esse é um recurso da linguagem, a interface AutoCloseable não faz parte do pacote java.io, ao contrário da interface Closeable, mas do package java.lang. Assim o bloco finally poderia ser removido sem prejuízo nenhum a lógica do programa.
try (Reader reader = /* inicia reader */) {
// lê dados
} catch (IOException ioe) {
// trata exceção
}Agora que sabemos que (1) objetos de I/O devem liberar recursos e que as classes de I/O são do tipo Closeable, observe as principais classes do pacote. Vamos explorar um pouco delas.


Casos de Uso
Para explorar melhor essas classes, vamos dividir o pacote em 5 casos de usos bem comuns para biblioteca I/O.
-
Como ler um arquivo?
-
Como escrever um arquivo?
-
Como ler dados do console?
-
Como ler/escrever em Socket?
-
Lidando objetos complexos
1. Como ler um arquivo?
Falamos anteriormente que a diferença entre um InputStream e um Reader é que o InputStream trabalha com bytes enquanto o Reader com caracteres. Agora vamos mostrar um exemplo prático? Imagina que você tem um arquivo texto em formato JSON, como fazer pra o ler? Se pensou em ler usando um Reader… vá com calma! A primeira coisa a fazer é decidir qual biblioteca vai ser usada para ler o JSON. A escolha deve começar pelo elemento mais complexo.
Para se ler um JSON, temos uma biblioteca praticamente onipresente: Jackson Databind! O coração dessa biblioteca é a classe ObjectMapper e ela define várias formas de se escrever em arquivo, a forma mais fácil nem chega a usar Stream ou Readers. O código abaixo foi retirado a própria documentação do ObjectMapper, observe que não se usa nem InputStream/OutputStream ou Readers/Writers.
final ObjectMapper mapper = new ObjectMapper(); // can use static singleton, inject: just make sure to reuse!
MyValue value = new MyValue();
// ... and configure
File newState = new File("my-stuff.json");
mapper.writeValue(newState, value); // writes JSON serialization of MyValue instance
// or, read
MyValue older = mapper.readValue(new File("my-older-stuff.json"), MyValue.class);
// Or if you prefer JSON Tree representation:
JsonNode root = mapper.readTree(newState);
// and find values by, for example, using a JsonPointer expression:
int age = root.at("/personal/age").getValueAsInt();Mas isso não impede que se use eles para ler dados de um arquivo. A primeira missão que temos é mapear o objeto que devemos ler como um POJO. Em um projeto pessoal eu criei uma interface para inspecionar Cluster Kafka, o Kafka Tool. Nesse projeto, todas as configurações são salvas em arquivos JSON no diretório ~/.kafka-tool (arquivos começados com . são considerados ocultos no Linux), assim para armazenar as informações de Brokers é preciso primeiro mapear um broker. Depois de mapeador o broker é preciso carregar a lista de brokers do arquivo, para isso basta usar o código abaixo.
Path kafkaToolConfigPath = PAths.get(System.getProperty("user.home"), ".kafka-tool");
if (!kafkaToolConfigPath.toFile().exists()) {
Path propertiesPath = kafkaToolConfigPath.resolve("kafka-properties.json");
if (propertiesPath.toFile().exists()) {
try (BufferedReader reader = Files.newBufferedReader(propertiesPath)) {
return Optional.of(reader.lines()
.collect(Collectors.joining()))
.filter(Predicate.not(String::isBlank))
.flatMap(value -> handleIoException(() -> mapper.readValue(value, KafkaBroker[].class)));
} catch (IOException e) {
logger.error("Error reading file!", e);
}
}
}
return Optional.empty();Para ler usamos um BufferedReader porque ele permite ler todo o arquivo em texto facilmente, para isso usamos a o método Files.newBufferedReader, que pode ser lido através do método ObjectMapper.readValue que aceita String. Mas também podíamos abrir um InputStream usando Files.newInputStream e usar ele diretamente como parâmetro ObjectMapper.readValue
2. Como escrever um arquivo?
De forma bem similar podemos escreve em arquivos usando as mesmas APIs.
Path kafkaToolConfigPath = PAths.get(System.getProperty("user.home"), ".kafka-tool");
if (!kafkaToolConfigPath.toFile().exists()) {
kafkaToolConfigPath.toFile().mkdir();
}
Path propertiesPath = kafkaToolConfigPath.resolve("kafka-properties.json");
ObjectMapper mapper = new ObjectMapper().enable(SerializationFeature.INDENT_OUTPUT)
try (BufferedWriter writer = Files.newBufferedWriter(propertiesPath, StandardOpenOption.CREATE, StandardOpenOption.TRUNCATE_EXISTING)) {
writer.write(mapper.writeValueAsString(brokers));
} catch (IOException e) {
logger.error("Error saving file!", e);
}Para escrever usamos um BufferedWriter, através do Files.newBufferedWriter, porque é uma opção viável para se usar com ObjectMapper.writeValueAsString. Mas da mesma forma podíamos usar OutputStream, através do Files.newOutputStream, porque também é uma opção viável para se usar com ObjectMapper.writeValueAsBytes
3. Como ler dados do console?
Toda aplicação pode rodar em modo de linha de comando. Linha de comando é bastante útil porque possibilita que as aplicações sejam integradas a scripts de execução seguindo a Filosofia Unix: Escreva programas para lidar com fluxos de texto, porque essa é uma interface universal.
A primeira informação importante é saber que os streams de entrada, saída e erro estão expostos como variáveis globais na classe System. Assim podemos facilmente escrever um programa que lê da linha de comando com algumas linhas.
try(BufferedReader reader = new BufferedReader(new InputStreamReader(System.in))) {
String name = reader.readLine();
System.out.println(name);
}Esse código é certo e funciona, mas existe uma outra classe que facilita em muito o tratamento de dados que vem do console, é a classe Scanner. Com ela é possível tratar os dados de entrada de forma mais fácil. Por exemplo se eu quiser fazer um programa para lê números do console, é possível fazer com poucas linhas.
try(Scanner in = new Scanner(System.in)) {
System.out.print("Qual o seu nome? ");
String nome = in.nextLine();
System.out.print("Quantos anos você tem? ");
int idade = in.nextInt();
System.out.println("Oi " + nome + "! Você tem " + idade + " anos!");
}4. Como ler/escrever em Socket?
Sockets devem ser usados com parcimônia! Sockets permitem que dois processos se comuniquem entre si através de uma conexão TCP direta. O problema em usar Sockets é que em muitos casos você pode estar reimplementando um protocolo já conhecido. Mas as vantagens de se usar socket é que seu programa vai ter liberdade de se comunicar. Quando temos dois programas se comunicando por socket um deles será o cliente e o outro será o servidor, é o que chamamos de Socket Server.
Não vamos entrar aqui em detalhes sobre como a classe Socket funciona, mas ao abrir um socket, ela vai dispor de dois Stream para leitura e escrita de dados. Assim podemos ter o servidor abaixo.
AtomicBoolean running = new AtomicBoolean(true);
ExecutorService threadPool = Executors.newFixedThreadPool(10); // thread para processar socket
try(ServerSocket server = new ServerSocket(5555)) { // abre socket na porta 5555
while (running.get()) {
Socket socket = server.accept(); // conexão aberta com cliente
threadPool.submit(() -> { // Se não tratar dentro de uma thread não é possível abrir outras conexões
try {
process(socket.getInputStream(), // encapsula toda comunicação
socket.getOutputStream());
} finally {
socket.close(); // Só fecha o socket depois de finalizada a comunicação
}
});
}
}Já o cliente é um pouco mais simples porque não se espera que ele se conecte com mais de um servidor.
try (Socket socket = new Socket("localhost", 5555)) {
process(socket.getInputStream(), socket.getOutputStream());
}Eu não recomendo a você escrever um servidor socket em nenhuma hipótese. Caso você tenha um protocolo complexo que deve ser feito através de um servidor socket, eu recomendo usar o projeto Netty para que você consiga focar nas regras de negócios deixando funcionalidades como serialização, controle de threads e segurança como responsabilidade da biblioteca.
5. Lidando objetos complexos
Se você foi atento deve ter reparado que no diagrama de classe tem duas classes que parecem bastante úteis: ObjectInputStream e ObjectOutputStream. Essas duas classes permitem serializar qualquer objeto da JVM e enviar para outra JVM, é por causa dessas classes que existe a interface Serializable a qual eu citei na minha primeira pergunta e até agora não respondi. Pois vamos entender o motivo de deixar essa resposta por último?
Para serializar um objeto eu devo usar a interface Serializable? Não! Você pode usar qualquer biblioteca com formatos de serialização que são compreendidos por várias linguagens. A interface Serializable é usada para serializar objetos que só podem ser carregados na JVM através das classes ObjectInputStream e ObjectOutputStream. MAS essas classes não deve ser usadas porque elas tem várias falhas de segurança que podem ser exploradas. Então resposta curta: Não use essas classes!
Próximos passos
Eu espero que você tenha compreendido que como ler dados de várias fontes como arquivos ou sockets. Agora é hora de você aprender a usar bibliotecas de leituras de arquivos. Recomendo que você explore a biblioteca Jackson, assim como outras bibliotecas para se escrever JSON. Um bom exercício é comparar a performance de escrita entre várias bibliotecas e escolher a que você vai usar sempre.
Paralelismo e Concorrência
Esse post faz parte de uma série introdutória sobre Java, se você não conhece a linguagem e não leu os posts anteriores, recomendo os ler para ter uma visão melhor da plataforma. Nessa série, já falamos sobre o que é o ecossistema Java, o que é a biblioteca Collections, como Java faz Orientação a Objetos e o que é a biblioteca I/O, esses tópicos são necessários para o que vamos falar agora: Concorrência e Paralelismo.
O que é Concorrência e Paralelismo?!?
Nos frameworks modernos é muito raro lidarmos com paralelismo, apesar que podemos lidar com concorrência o tempo inteiro. Para entender isso precisamos primeiro compreender a diferença entre esses dois conceitos. Para isso vamos imaginar que estamos em uma biblioteca, nessa biblioteca tem dois tipos de livros: os comuns e os raros. Os livros comuns estão acessíveis na estantes para que todos possam ler e pegar emprestado, mas os livros raros estão disponíveis em uma sala especifica em que você precisa pedir para um bibliotecário pegar ele e deve ler somente na sala.
Vamos imaginar que surgiu um estranho interesse por se ler livros raros na cidade e isso gerou uma procura inesperada que surpreendeu até mesmo a direção da biblioteca.
— Todos estão disponíveis na internet! Só acessar o Projeto Gutenberg!!!
Isso gerou uma fila enorme na sessão de livros raros pois só tinha um bibliotecário para encontrar o livro, registrar a saída e ele ainda precisava observar se o livro estava sendo manipulado corretamente. Logo surgiram várias opções de como melhorar o atendimento da biblioteca, mas só poderiam ser consideradas as opções que mantivessem o cuidado para com as obras.

A primeira opção foi contratar mais um bibliotecário. Feita a contratação ele começou a dividir as tarefas com o mais antigo. Enquanto o primeiro cuidava de encontrar as obras e registrar as saídas, o segundo fiscalizava se todos os usuários da biblioteca estavam manuseando corretamente o livro.
A direção da biblioteca achou a opção boa, mas eles perceberam que o aumento da eficiência foi de apenas 30% enquanto se esperava 100% de eficiência com a contratação de um novo funcionário. Isso aconteceu porque as atividades foram distribuídas, mas nenhuma atividade era feita em paralelo. A atividade que mais demandava tempo era encontrar a obra e registrar a sua saída com cerca de 90% do tempo, logo essa atividade deveria ser feita em paralelo. Paralelismo acontece quando a mesma tarefa é realizada simultaneamente por mais de um bibliotecário. Assim os dois bibliotecários decidiram que iriam trabalhar em todo o conjunto de atividades aumentando a eficiência de 30% para 50%.
Mas eles encontraram um pequeno problema, só havia um computador na bancada e por isso eles precisavam se revesar para usar o computador. No começo eles replicavam a atividade que faziam quando havia apenas 1 bibliotecário: atendiam o cliente, encontravam o livro e registravam a saída. Mas perceberam que o tempo de registrar o livro também era demorado, ele demorava cerca de 3 vezes o tempo de pegar o livro, pois o software era bem lento e implementado em Javascript. Logo eles foram procurar solução para o problema deles e descobriram que estavam enfrentando um problema de concorrência. Concorrência acontece quando dois ou mais bibliotecários desejam acessar recursos limitados.
Eles perceberam que o mais demorado era entrar no sistema, logo resolveram atender 3 clientes por vez. Assim cada bibliotecário pegava o pedido de 3 clientes e depois registravam no sistema. Essa abordagem fez com que o atendimento se tornasse 70% mais eficiente do que era quando se tinha apenas um funcionário.
Por fim a biblioteca decidiu contratar uma bibliotecária para fiscalizar o manuseio dos livros porque percebeu que só tinha homens nessa história. E o aumento de eficiência passou para 150% pois ela conseguia fiscalizar e atender na bancada quando possível.
Eu espero que com essa história você tenha compreendido que esse processo acontece com qualquer servidor web. É EXATAMENTE ASSIM! Pense que a biblioteca é o servidor, os bibliotecários são threads, os livros são os recursos que o servidor usa e os clientes são os clientes que estão acessando a API do servidor. Eu não sei se os conceitos de concorrência e paralelismo são usado na bibliotecas, eles são conceitos da computação que foram usado nesse texto para descrever e diferenciar eles. Logo podemos redefinir Paralelismo quando a mesma tarefa é realizada simultaneamente por mais de uma thread ou processo e Concorrência quando acontece duas ou mais threads, ou processos desejam acessar recursos limitados.
O que é Thread e Processo?!?
Falar de Paralelismo e Concorrência não é uma tarefa fácil porque envolve vários conceitos de vários níveis. Até agora nós falamos de conceitos abstratos, mas agora vamos falar de algo bem mais concreto. Eu citei Thread e Processo e esses são conceitos sobre o sistema operacional.
Um processo é um programa rodando na memória. Ele é instanciado pelo sistema operacional e terá seu ciclo de vida até ser encerrado por si mesmo ou pelo próprio sistema operacional. Cada processo tem um identificador único e compartilha os recursos da máquina com outros processo. No trecho abaixo vemos a listagem dos 9 primeiros processos iniciados pelo Linux que ainda estão em execução, observe que o PID é o identificado único de cada processo, se eu quiser finalizar um processo preciso enviar um comando kill -15 <PID> onde -15 é o sinal que o programa deve ser encerrado, se eu usar -9 ele será encerrado imediatamente.
$ ps -aux | head
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 202552 5172 ? Ss Jul01 70:40 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
root 2 0.0 0.0 0 0 ? S Jul01 0:05 [kthreadd]
root 4 0.0 0.0 0 0 ? S< Jul01 0:00 [kworker/0:0H]
root 6 0.0 0.0 0 0 ? S Jul01 0:35 [ksoftirqd/0]
root 7 0.0 0.0 0 0 ? S Jul01 0:07 [migration/0]
root 8 0.0 0.0 0 0 ? S Jul01 0:00 [rcu_bh]
root 9 0.0 0.0 0 0 ? S Jul01 37:47 [rcu_sched]
root 10 0.0 0.0 0 0 ? S< Jul01 0:00 [lru-add-drain]
root 11 0.0 0.0 0 0 ? S Jul01 0:22 [watchdog/0]Se fossemos falar em processos no nosso exemplo da biblioteca, teríamos que criar uma biblioteca nova. Como eu disse, dois processo compartilham recursos mas isso não significa que eles podem acessar o mesmo recurso ao mesmo tempo. Por exemplo, se eu tenho um servidor rodando na porta 80, não posso iniciar outro processo na porta 80. Um processo não tem acesso a memória de outro processo, isso significa que para um mesmo objeto não pode existir em dois processos diferentes. (Até pode, mas não vamos falar de RMI porque é complicado e já foi removido da biblioteca padrão do Java.)
— E se eu quiser que as requisições que cheguem na porta 80 sejam processadas em paralelo, como faço?!?!
Lembra da nossa biblioteca? Pois é, cada biblioteca é um processo, mas cada bibliotecário é uma Thread. Thread são dois fluxos que compartilham o mesmo espaço de memória, ou seja, é quando um processo tem dois fluxos de execução em paralelo compartilhando recursos. Threads podem acessar a mesma porta, assim como podem acessar os mesmo objetos. Mas ele não podem ser feitas ao mesmo momento. Lembra do computador do balcão da biblioteca? A metáfora da biblioteca foi construída para similar exatamente o que acontece em um computador.
Thread e Processo em Java
Vamos agora mostrar algumas classes que podemos usar para manipular processos e threads usando Java. Uma das preocupações da plataforma Java foi criar uma abstração para que o mesmo código possa ser usado em qualquer sistema operacional, logo todo o código demonstrado pode ser executando tando em Linux quando Windows e sistemas derivados do Unix como o MacOS.
Processos
Para que possamos acessar as informações de todos os processos em execução podemos usar a classe ProcessHandle (adicionada no Java 9). Navegue pela documentação dela para perceber que processos podem ter uma relação de parentescos como podemos perceber através dos métodos children(), descendants() e parent(). Na execução abaixo vemos as informações do processo atual e a listagem de todos os processos em execução.
$ jshell
| Welcome to JShell -- Version 18
| For an introduction type: /help intro
jshell> System.out.println(ProcessHandle.current().pid());
System.out.println(ProcessHandle.current .pid() );
20092
jshell> System.out.println(ProcessHandle.current().info());
System.out.println(ProcessHandle.current .info );
[user: Optional[VEPO], cmd: C:\Users\vepo\.sdkman\candidates\java\18-open\bin\java.exe, startTime: Optional[2022-09-02T18:49:28.093Z], totalTime: Optional[PT0.328125S]]
jshell> ProcessHandle.allProcesses().forEach(System.out::println);
ProcessHandle.allProcesses .forEach(System.out::println);
0
4
72
[...]Caso você deseje criar um novo processo, é preciso fazer uma chamada de sistema usando a classe Runtime. No trecho de código abaixo usamos o método exec para criar um novo processo.
jshell> Runtime.getRuntime().exec("pwd")
Runtime.getRuntime .exec("pwd")
$4 ==> Process[pid=19628, exitValue="not exited"]Na resposta da execução podemos ver que o método exec retorna o novo processo, mas não espera por ele terminar, retornando apenas um objeto Process para poder ser manipulado. Em posse desse objeto, podemos esperar por ele terminar e ver se a execução foi um sucesso.
jshell> Runtime.getRuntime().exec("pwd").waitFor()
Runtime.getRuntime .exec("pwd").waitFor
$5 ==> 0Percebeu que o método waitFor retornou 0? Todo processo precisa finalizar com um número e zero significa sucesso. Qualquer número diferente de zero significa que o programa foi finalizado com erro. O programa que eu executei acima é o pwd que retorna o diretório corrente em Linux, apesar de usar Windows uso o Git Bash que é um porte do MinGW que simula um bash Linux.
Threads
Threads também são criadas pelo sistemas operacional, mas o Java dá suporte a duas bibliotecas bem interessantes que precisamos demonstrar. A primeira é a classe Threads que deve ser usada com muita parcimônia essa classe, o livro Java Efetivo nos diz no Item 80: Dê preferência aos executores, às tarefas e às streams em vez de threads. Os Executors são a proxima classe que vamos ver que podem entregar as mesmas funcionalidades.
— Então porque entender Threads?!?!
Threads são importantes porque são um conceito do sistema operacional. Um executor não elimina uma thread, ele apenas facilita a implementação delas e otimiza o seu uso. Threads são gerenciadas pelo Sistema Operacional. O tempo de CPU será dividido entre os processos e as threads. Isso significa que se seu computador tem 4 CPUs e seu programa tem ao menos 2 threads, é provável que em algum momento seu programa esteja rodando em 2 CPUs ao mesmo tempo, mas quem define isso é o sistema operacional.
Threads são um recurso do sistema operacional limitado e caro. No Windows isso não é transparente, mas no Linux é possível acessar essas informações facilmente através do arquivo /proc/sys/kernel/threads-max. Na execução abaixo vemos que essa instância do Linux só pode rodar 32.768 processos concorrentes e 100.435 threads concorrentes, o que dá em média 3 threads por processo.
$ cat /proc/sys/kernel/threads-max
100435
$ cat /proc/sys/kernel/pid_max
32768— Mas 3 threads por processo não é muito pouco?!?!
Não! Porque é praticamente impossível rodar 32.768 processos concorrentes e a grande maioria dos processos tem apenas uma thread rodando.
— Mas o que acontece quando o Java pede uma thread nova?
Para entender isso, precisamos compreender outro conceito importante de Sistemas Operacionais o espaço do usuário e o espaço do kernel (user space e kernel space). Espaço do usuário é todo o código dos nossos programas, já o espaço do kernel é o código do sistema operacional que nossos programas usam para realizar algumas operações. Toda operação que sai do espaço do usuário e vai para o espaço do kernel é custosa porque pode envolver recursos compartilhados como sockets, arquivos ou threads. Logo, criar uma nova thread é custoso porque tem que criar uma nova thread no sistema operacional que não é apenas alocar um espaço na memória.
No código abaixo uma thread é criada que sua única função é pegar o instante em que é iniciada, dormir por 500ms e armazenar o instante em que ela é finalizada. Os tempos deve ser armazenados no array tempos porque nenhuma variável pode ser alterada diretamente entre duas threads que não seja uma variável final, pois estamos falando de duas pilhas de execução diferentes.
long[] tempos = new long[4];
tempos[0] = System.nanoTime();
Thread t = new Thread() {
@Override
public void run() {
tempos[1] = System.nanoTime();
try {
Thread.sleep(500);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
tempos[2] = System.nanoTime();
}
};
t.start();
try {
t.join();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
tempos[3] = System.nanoTime();
System.out.println(String.format("Tempo de inicialização: %dµs", (tempos[1] - tempos[0]) / 1000));
System.out.println(String.format("Tempo de execução : %dµs", (tempos[2] - tempos[1]) / 1000));
System.out.println(String.format("Tempo total : %dµs", (tempos[3] - tempos[0]) / 1000));O resultado da execução é o visto abaixo, observe que demora quase meio milissegundo para que a thread seja iniciada. Esse tempo pode parecer pouco, mas se houver um uso abusivo dessa classe pode impactar a performance, pois esse tempo é latência adicionada ao processamento.
Tempo de inicialização: 436µs
Tempo de execução : 510061µs
Tempo total : 510643µsObserve também que usamos os métodos start e join, eles servem para controlar a thread. Uma thread não inicia sua execução imediatamente, é preciso que o código que a instanciou dispare a execução. Mas quando a execução se inicia os dois códigos começam a ser executados em paralelo, para que se aguarde a finalização da thread é preciso usar o método join que fará com que a thread corrente seja bloqueada até que a outra seja finalizada.
Outro ponto importante é o uso da exceção InterruptedException, ela é lançada pela JVM toda vez que a thread é interrompida pelo sistema operacional.
— Mas o que significa a thread ser interrompida pelo sistema operacional?
Ora, já teve vezes em que uma janelinha do Windows ficou não responsiva e você foi lá forçou ela a ser fechada? Ou você executou um comando no bash e não quis esperar a resposta e pressionou CRTL + C. Nessa hora o sistema operacional envia um sinal ao programa que ele deve finalizar, o SIGTERM. Quando esse sinal é recebido pela thread, ela deve liberar todos os recursos e se finalizar, por isso quanto tempos uma InterruptedException é hora de limpar a casa e fechar tudo.
Se você ignorar essa exception, o seu processo pode virar um processo zumbi, pois outras threads podem ter obedecido o sinal e já ter finalizada criando instabilidade para a execução. Então, recebeu um InterruptedException, fecha tudo e chama Thread.currentThread().interrupt().
Há um outro sinal que não fornece essa informação, o SIGKILL, o sistema operacional simplesmente mata a execução sem nenhuma educação e protocolo.
Por fim, você deve ter reparado que implementamos o método run na thread. Esse método é definido na classe Runnable, essa classe é muito importante porque nem sempre precisamos definir uma thread nova, podemos estender essa classe e criar quantas threads forem necessária com o mesmo código.
Existe a possibilidade de se criar grupos de threads com a classe ThreadGroup, mas não vamos abordar ela porque todas as funcionalidades delas podem ser endereçadas com Executors.
Executors
Executors são a nova, em relação a Thread, biblioteca adicionada no Java 5 que permite um controle melhor sobre Threads e grupos de threads. A vantagem do uso da classe Executors é que temos uma interface bem mais interessante, como veremos a diante. Primeiro vamos focar em performance.
Como falamos, criar thread pode ser uma operação cara, com executors podemos criar pool de threads ou reutilizar threads já existentes sem a necessidade de se criar novas threads. Se compararmos a execução vemos que o uso de pools de thread diminuem o tempo gasto com a inicialização dessas threads. Nos teste que executamos, vemos que o tempo de inicialização e o tempo médio total são menores, somente o tempo médio de execução é maior, mas isso é devido a fatores externos ao código já que executamos o mesmo código em ambos o caso.
Usando Threads
Tempo de inicialização: 402µs
Tempo de execução : 511415µs
Tempo total : 511939µs
Tempo médio de inicialização: 77370µs
Tempo médio de execução : 50792817µs
Tempo médio total : 50880048µs
Usando Executors
Tempo de inicialização: 2829µs (+2.427µs)
Tempo de execução : 509877µs (-1.538µs)
Tempo total : 513237µs (+1.298µs)
Tempo médio de inicialização: 19708µs (-57.662µs)
Tempo médio de execução : 50806122µs (+13.305µs)
Tempo médio total : 50839674µs (-40.374µs)Para se criar um ExecutorService deve se usar a classe Executors. Nessa classe tempos vários tipos de ExecutorServices, mas os mais importantes são os FixedThreadPool, CachedThreadPool e ScheduledThreadPool. Cada um desses tem suas peculiaridades que não vamos abordar aqui, apenas vamos ressaltar que ScheduledThreadPool deve ser usado quando precisamos criar threads que executam em intervalos pré definidos.
long[] tempos = new long[4];
tempos[0] = System.nanoTime();
ExecutorService executor = Executors.newSingleThreadExecutor();
Future<?> ft = executor.submit(() -> {
tempos[1] = System.nanoTime();
try {
Thread.sleep(500);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
tempos[2] = System.nanoTime();
});
try {
ft.get();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
tempos[3] = System.nanoTime();
System.out.println(String.format("Tempo de inicialização: %dµs", (tempos[1] - tempos[0]) / 1000));
System.out.println(String.format("Tempo de execução : %dµs", (tempos[2] - tempos[1]) / 1000));
System.out.println(String.format("Tempo total : %dµs", (tempos[3] - tempos[0]) / 1000));
executor.shutdown();A grande diferença é que quando criamos uma nova execução o ExecutorService retorna um Future que irá prover informações sobre a execução e o retorno da execução. Um executor não aceita apenas um Runnable, mas também Callable que retorna valores. A opção por usar Callable irá tornar seu código mais legível.
Outro ponto importante do uso de ExecutorService é que assim que uma nova atividade é submetida, ela entrará na fila de execução. É preciso ressaltar que ela só será executada quando houver thread disponível. Isso significa que um ExecutorService deve ser usado para atividades rápidas e não com longa duração. Se você precisar executar algo que dure toda execução crie um ExecutorService de tamanho pré-definido, usando newFixedThreadPool ou cria a thread manualmente.
Por fim um ExecutorService não finaliza automaticamente, ele deve ser finalizado através do método shutdown. Caso você não chame esse método o seu programa vai virar um processo zumbi.
Controle de Concorrência
Como vimos concorrência é um problema diferente de paralelismo, ela é a solução para garantir que apenas uma thread está executando um trecho de código. As soluções de concorrência da JVM são propostas para que seja usadas dentro de uma mesma instância da JVM, ou seja, não é possível pela biblioteca padrão garantir concorrência entre dois processos distintos.
Vamos começar a ver pelos modos mais antigos, mesmo que eles já não sejam os mais utilizados. O primeiro dele é o mais simples de todos, usar o modificado synchronized. No trecho de código abaixo, o synchronized permite que o de counter seja impresso na linha de comando sequencialmente, caso seja removido valores repetidos e fora de ordem aparecerão. O synchronized vai garantir que quando uma thread está executando o método printAndIncrement as outras serão bloqueadas até que a execução seja finalizada. Quando usamos o synchronized em um método de instância, o efeito do bloqueio só acontece quando método de um mesmo objeto são executados concorrentemente, caso o controle de concorrência deva ser feito globalmente o synchronized pode ser usado em métodos estáticos.
public class Sync {
private int counter;
public Sync() {
counter = 0;
}
public synchronized void printAndIncrement() {
counter++;
System.err.println(String.format("Thread [%s] valor:%d", Thread.currentThread().getName(), counter));
}
}Usar o modificador synchronized ainda é uma prática bem comum apesar que existem soluções melhores. Ele deve ser usado quando é realmente necessário bloquear todo o bloco de execução. Se você precisa usar em uma das classes da biblioteca Collection (vista na sessão 3) a melhor solução é usar uma das classes da biblioteca padrão do Java. A classe Collections tem alguns métodos que criam um envolucro para objetos, por exemplo, se eu tenho uma lista e desejo usar ela em várias threads, eu posso usar Collections.synchronizedList(minhaLista).
Observe no trecho de código abaixo que temos duas listas mas apenas a segunda pode ser usada em várias threads. Qualquer operação na segunda lista reflete na primeira. Usar uma lista não sincronizada pode ser que não faça o programa apresentar uma exceção, mas com certeza vai criar estados inconsistentes.
$ jshell
| Welcome to JShell -- Version 18
| For an introduction type: /help intro
jshell> List<String> minhaLista = new ArrayList<>();
List<String> minhaLista = new ArrayList<> ;
minhaLista ==> []
jshell> List<String> minhaListaSync = Collections.synchronizedList(minhaLista);
List<String> minhaListaSync = Collections.synchronizedList(minhaLista);
minhaListaSync ==> []
jshell> minhaLista.add("String 1")
minhaLista.add("String 1")
$3 ==> true
jshell> minhaListaSync.add("String 2")
minhaListaSync.add("String 2")
$4 ==> true
jshell> minhaLista
minhaLista
minhaLista ==> [String 1, String 2]
jshell> minhaListaSync
minhaListaSync
minhaListaSync ==> [String 1, String 2]O synchronized também pode ser usado como bloco de código, mas essa é uma forma um pouco arcaica como veremos. Vamos imagina que temos duas threads, uma produzindo valores e a outra consumindo. A thread que consome valores deve sempre retornar um valor, não importa se não existe valores no momento. Normalmente isso é o que acontece quando temos um buffer em quem uma thread está produzindo e outra consumindo.
public class Buffer {
private Object lock = new Object();
private List<int[]> _buffer = new LinkedList<>();
public void add(int[] valores) {
synchronized(lock) {
_buffer.add(valores);
lock.notifyAll();
}
}
public int[] consume() {
int[] nextValue = null;
synchronized(lock) {
while(_buffer.isEmpty()) {
lock.wait();
}
nextValue = _buffer.remove(0);
}
return nextValue;
}
}A classe acima está implementada usando técnicas que não devem mais ser usadas. O primeiro problema é que toda chamada ao bloco sincronizado será feita por apenas uma thread por vez, existe técnicas mais recentes que permitem que mais de uma thread acessem um bloco sincronizado que veremos a seguir. O bloco sincronizado deve ser feito usando um objeto em comum, no caso esse objeto pode ser compartilhado em mais de um objeto, caso a thread deseje esperar por alguma condição, deve se usar o método wait que será despertado por uma chamada ao método notify ou notifyAll. No exemplo acima, se não há valores a serem consumidos, eles devem esperar por um valor.
Uma alternativa ao bloco sincronizado é o uso da classe ReadWriteLock. A necessidade dessa classe surgem quando se percebe que apenas as threads que escrevem devem ter acesso exclusivo, as threads de leitura podem acessar os métodos livremente. No exemplo acima não é possível usar ela porque ambos os métodos escrevem ao adicionar e remover valores na lista por isso serão necessárias algumas alterações.
public class Buffer {
private final ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private final Lock readLock = readWriteLock.readLock();
private final Lock writeLock = readWriteLock.writeLock();
private final Condition newItem = writeLock.newCondition();
private final List<int[]> _buffer = new LinkedList<>();
public void add(int[] valores) {
writeLock.lock();
try {
_buffer.add(valores);
newItem.signalAll();
} finally {
writeLock.unlock();
}
}
public int available() {
readLock.lock();
try {
return _buffer.size();
} finally {
readLock.unlock();
}
}
public int[] consume(int position) {
readLock.lock();
try {
while (_buffer.size() <= position) {
newItem.await();
}
return _buffer.get(position);
} finally {
readLock.unlock();
}
}
}Na nossa nova classe Buffer, quem é responsável por saber a posição no buffer é a thread que consome que pode ser mais de uma. Cada chamada ao método consome e available poderão ser feitas sem nenhum bloqueio. Mas se uma chamada ao método add for feita, ela deverá esperar pela finalização de todas as chamadas aos locks de leitura e todos os locks de leitura deverão esperar pela finalização do lock de escrita. Os locks de leitura podem ser executados concorrentemente, mas o lock de escrita só pode acontecer quando nenhum outro lock estiver ativo.
No código acima podemos ver também o uso da classe Condition. Essa classe deve ser usada quando esperamos alguma condição especifica, no nosso caso é a lista ter o item desejado ou não. O uso dessa classe é bem similar ao dos métodos wait, notify e notifyAll, mas é adicionada uma melhor semântica pode podemos criar mais que uma condição e usar elas para dar uma boa legibilidade ao código.
Por fim a biblioteca padrão do Java tem uma série de classes atômicas que são extremamente úteis. Elas estão no pacote java.util.concurrent.atomic e todas elas tem comportamento similar, vão permitir você realizar operações atômicas sem se preocupar com a concorrência. Para demonstrar o uso delas vou mostrar o caso mais comum que é criar um contador sincronizado.
ExecutorService executor = Executors.newFixedThreadPool(15);
AtomicInteger counter = new AtomicInteger(0);
List<Future<?>> allFuture = new ArrayList<>();
for (int i = 0; i < 1_000; ++i) {
allFuture.add(executor.submit(() -> System.out.println("Contador: " + counter.incrementAndGet())));
}
executor.shutdown();
try {
executor.awaitTermination(1, TimeUnit.SECONDS);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}No código acima não podemos garantir que os valores impressos estarão em ordem, mas podemos garantir que todos os valores de 1 a 1000 serão impressos. A classe AtomicInteger garante que a operação incrementAndGet seja feita atomicamente, isso significa que ela não será interrompida por outra chamada a outro método desse mesmo objeto. Todas as classes desse pacote merecem nossa atenção pois elas são bem importantes, principalmente se você está desenvolvendo um aplicativo Desktop que irá lidar com várias threads.